📝 Paper Summary
Vision-Language-Action (VLA) models
Robotic manipulation
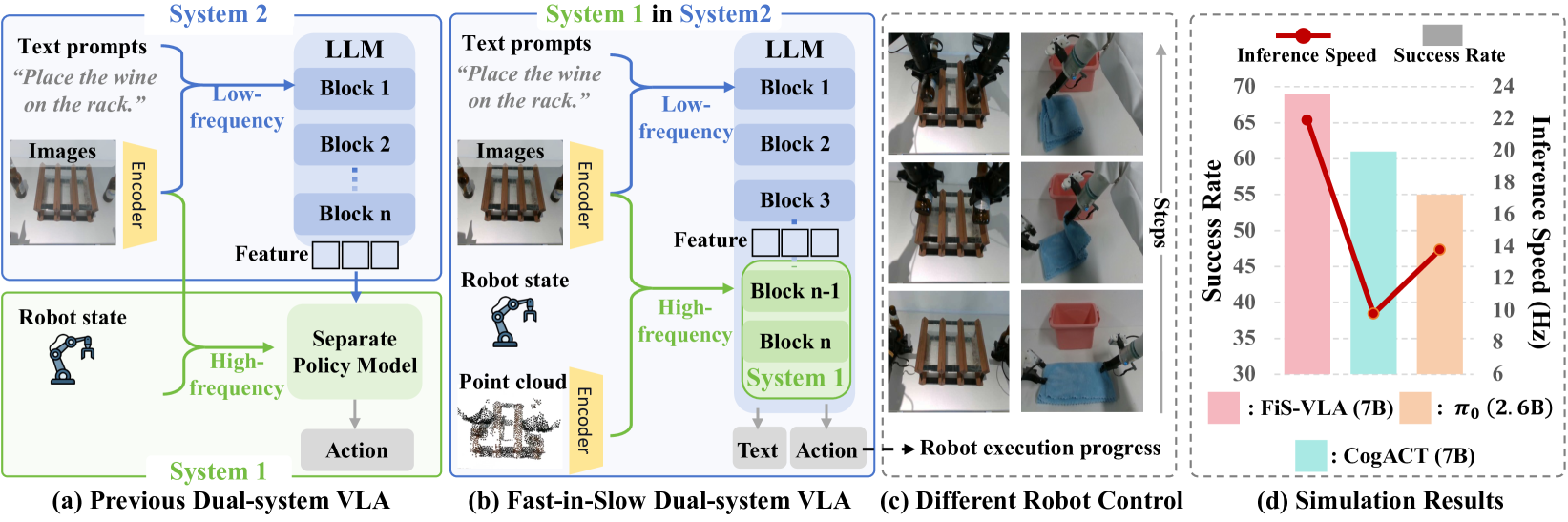
Dual-system AI
FiS-VLA integrates a fast diffusion-based execution module directly into the final layers of a slow reasoning VLM, enabling high-frequency control without sacrificing semantic understanding.
Core Problem
Current Vision-Language-Action (VLA) models are either too slow for real-time control (due to massive parameters) or rely on separate, disjointed policy heads that fail to fully leverage the VLM's pretrained knowledge.
Why it matters:
- Low operating frequencies in large VLMs (e.g., <5 Hz) cause latency that makes responsive closed-loop robotic control impossible in dynamic environments.
- Existing dual-system approaches treat the fast policy (System 1) as a separate, lightweight appendage, preventing it from accessing the rich internal representations of the reasoning model (System 2).
Concrete Example:
A standard VLA might correctly reason 'pick up the red cup' but fail to adjust its grip in real-time if the cup slips, because the reasoning loop takes too long (e.g., 200ms) to generate the next action. Meanwhile, a separate fast policy might react quickly but forget the semantic instruction 'red cup' if the connection to the VLM is weak.
Key Novelty
Unified Fast-in-Slow Architecture (FiS)
- Repurposes the final transformer blocks of a large VLM (System 2) into a fast execution module (System 1) rather than attaching an external network.
- System 1 generates high-frequency actions via diffusion, conditioned on the slow System 2's latent reasoning features and real-time 3D/proprioceptive inputs.
- Uses an asynchronous design where System 2 updates high-level reasoning slowly (e.g., 1 Hz) while System 1 executes actions rapidly (e.g., 100+ Hz) using the most recent reasoning context.
Architecture
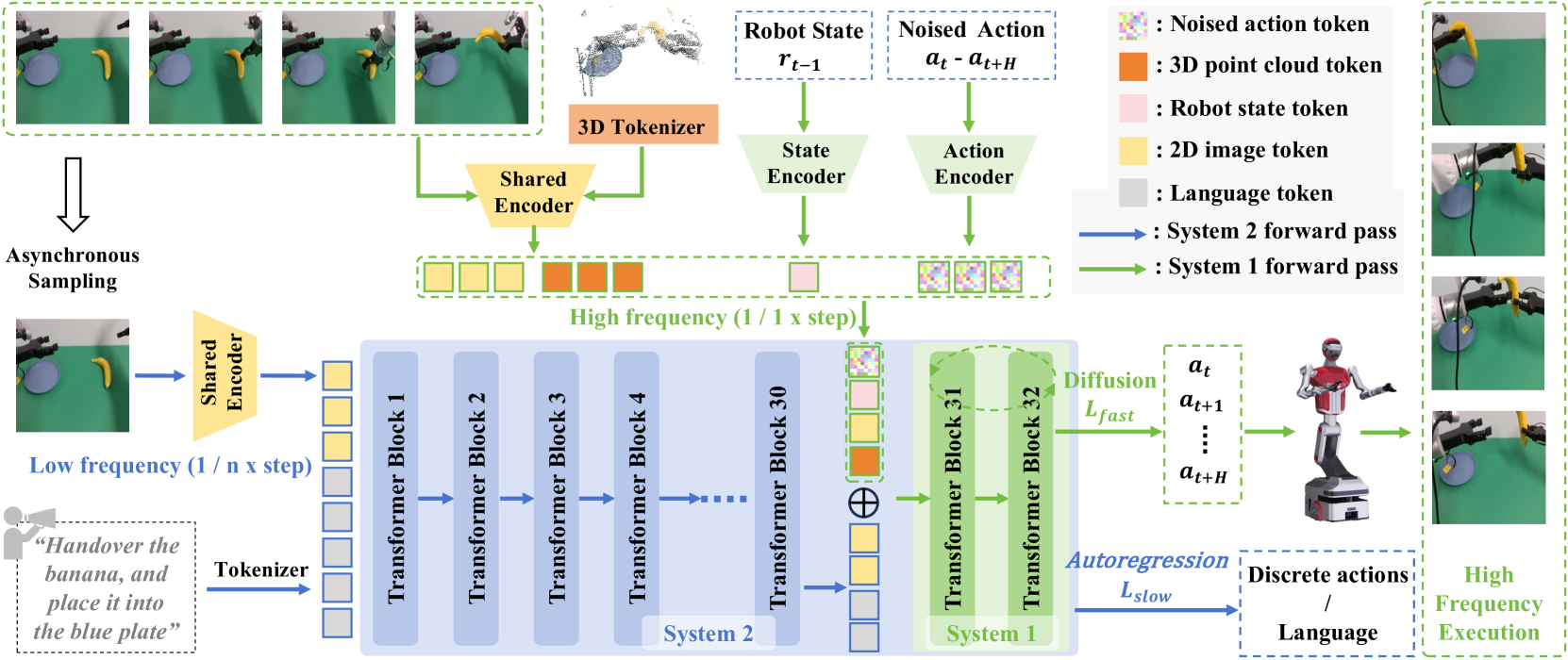
The overall architecture of FiS-VLA, showing the shared Vision Encoder, the System 2 VLM backbone, and the embedded System 1 execution module.
Evaluation Highlights
- Achieves 117.7 Hz control frequency on an NVIDIA 4090 GPU (with action chunking), significantly faster than autoregressive VLA baselines.
- Outperforms state-of-the-art OpenVLA by +11% success rate in real-world tasks and +8% in simulation.
- Demonstrates superior generalization to unseen objects and backgrounds compared to synchronous dual-system methods like CogACT.
Breakthrough Assessment
8/10
Significantly improves the practicality of VLA models by solving the inference speed bottleneck while maintaining reasoning capabilities, validated on real hardware.