📝 Paper Summary
Vision-Language-Action Models (VLAs)
Robot Manipulation
Sim-to-Real Transfer
RoboVLMs systematically isolates key VLA design choices, demonstrating that decoder-only backbones with continuous action policy heads and post-training on cross-embodiment data significantly outperform prior architectures.
Core Problem
Despite the promise of Vision-Language-Action (VLA) models, there is no consensus on the optimal backbone, architecture formulation (e.g., discrete vs. continuous, interleaved vs. policy head), or training recipe for effectively utilizing cross-embodiment data.
Why it matters:
- Current VLA research is fragmented, with different works using disparate backbones and recipes, making it hard to isolate sources of improvement
- Inefficient design choices (e.g., wrong action space or fusion method) lead to poor data efficiency and generalization in real-world robotics
- The assumption that simple co-training with large-scale cross-embodiment data automatically improves performance has not been rigorously validated
Concrete Example:
When a robot attempts a long-horizon task like 'rotate the block', models using discrete action spaces (like RT-2) suffer from compounding quantization errors, leading to failure, whereas the proposed continuous action formulation maintains precision.
Key Novelty
Systematic Design Framework for VLAs (RoboVLMs)
- Decouples VLA design into three axes: Backbone selection (evaluating 8+ VLMs), Architecture formulation (Policy Head vs. Interleaved, Continuous vs. Discrete), and Data strategy (Co-train vs. Post-train)
- Identifies 'Policy Head' formulation (preserving VLM tokens while using a separate head for history fusion) as superior to interleaving history directly into the context window
- Establishes a 'Post-training' recipe where models are pre-trained on cross-embodiment data and then fine-tuned on target data, rather than naive co-training
Architecture
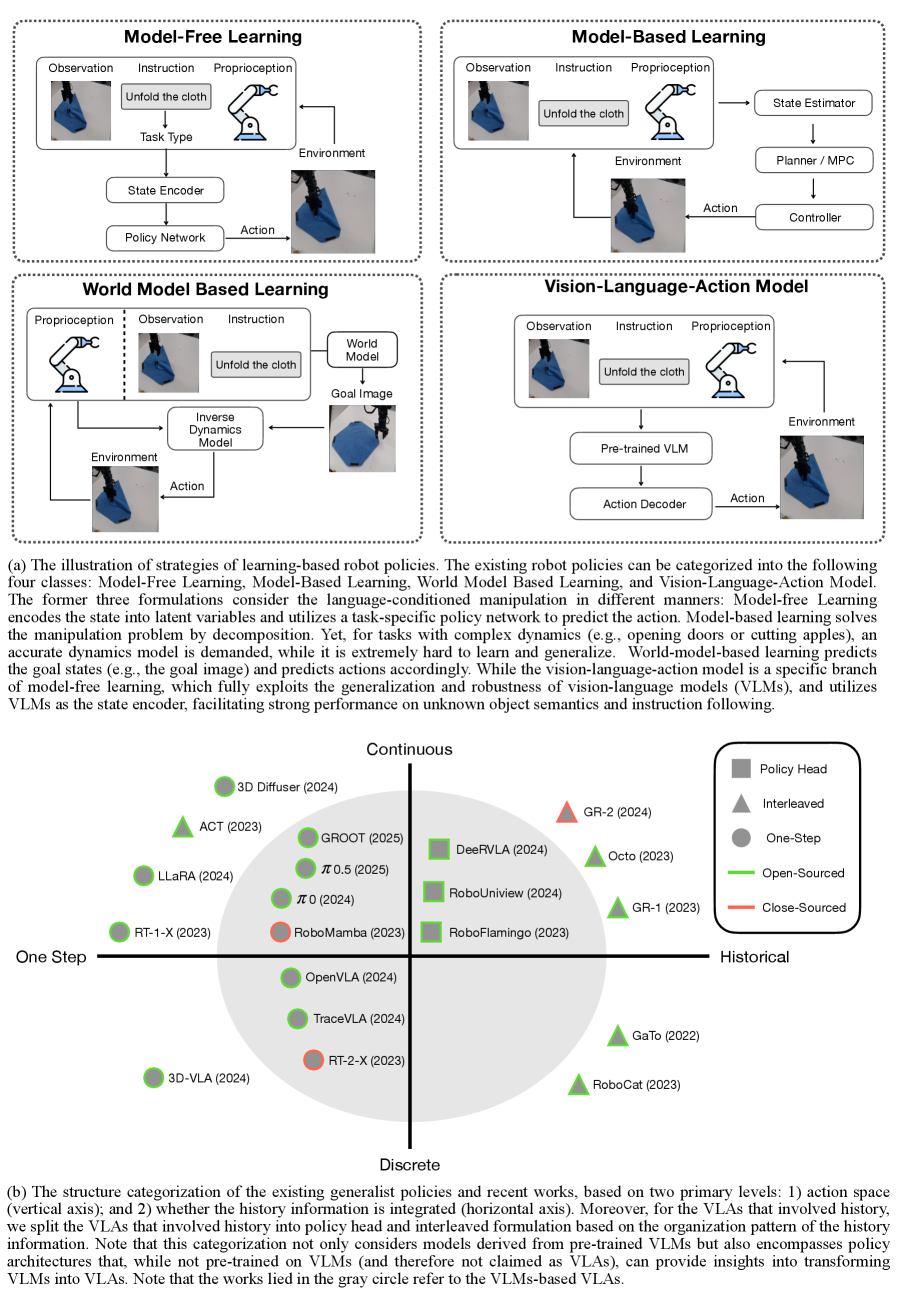
Categorization of VLA formulations: 1) One-step, 2) Interleaved History, 3) Policy Head History (Discrete), 4) Policy Head History (Continuous).
Evaluation Highlights
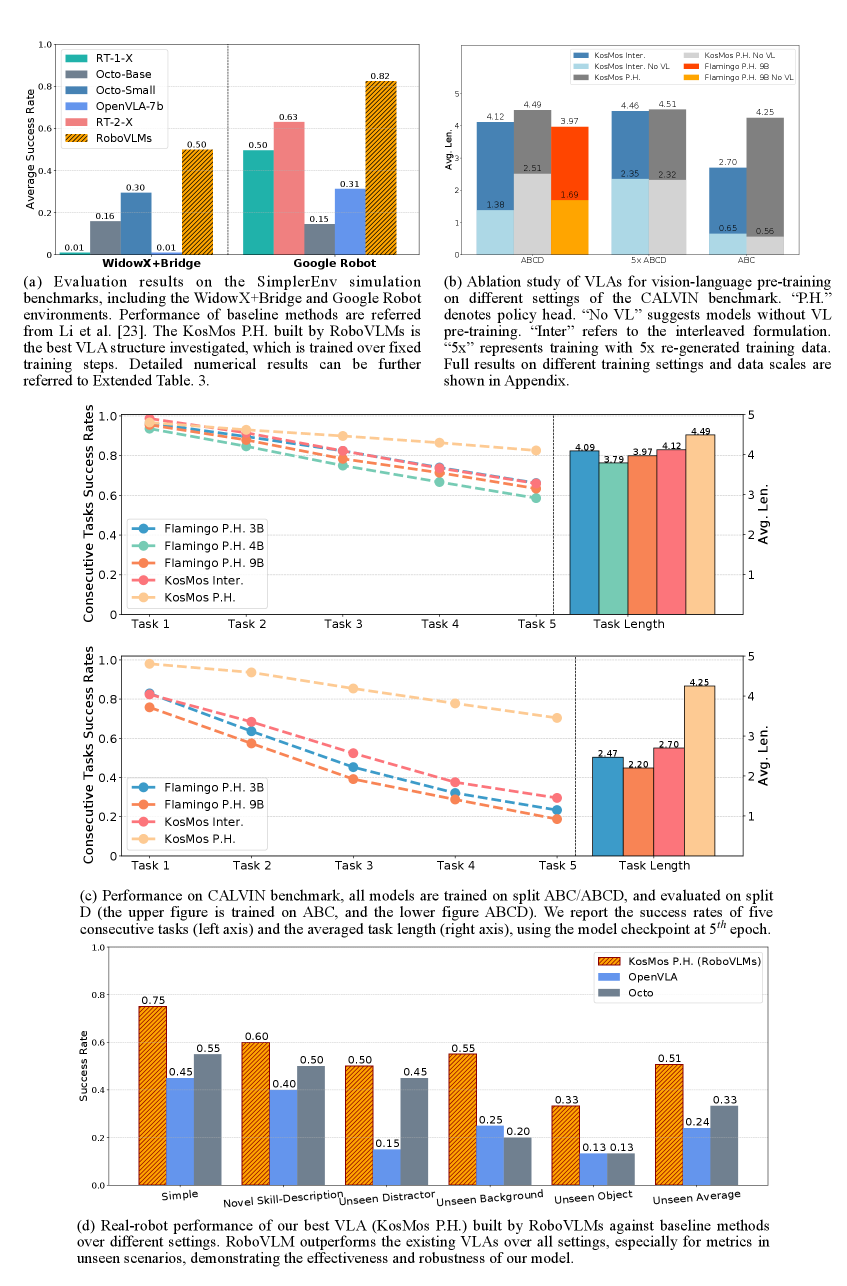
- +30.3% success rate improvement on 5 consecutive tasks in the CALVIN benchmark compared to the previous state-of-the-art (GR-1), specifically using the KosMos backbone
- Increases average task completion length from 3.06 (GR-1) to 4.25 (RoboVLM) on CALVIN zero-shot evaluation (Split D)
- Demonstrates strong real-world generalization across 4 unseen categories (distractors, backgrounds, objects, skill descriptions) using a KosMos-based VLA trained on just 74K trajectories
Breakthrough Assessment
8/10
While not proposing a single radical new architecture, the paper provides a crucial empirical grounding for the field, debunking common assumptions (like the efficacy of naive co-training) and setting a strong new SOTA baseline through rigorous ablation.