📝 Paper Summary
Medical Vision-Language Models
3D Medical Imaging Foundation Models
Merlin is a 3D foundation model for abdominal CT scans trained on paired images, text reports, and EHR diagnosis codes to enable versatile downstream clinical tasks without manual labels.
Core Problem
Existing medical vision-language models are primarily limited to 2D images and short text, failing to capture the 3D volumetric nature of CT scans and the rich context of long radiology reports.
Why it matters:
- Abdominal CTs are high-volume (25% of all CTs) and complex (300+ slices), contributing to radiologist burnout
- Current 2D approaches (slice-by-slice aggregation) are inefficient and miss 3D anatomical correlations essential for identifying pathologies
- Supervised ML requires expensive manual labeling, whereas hospitals have vast amounts of unlabelled paired data (images, reports, EHR codes) unused by current methods
Concrete Example:
A single abdominal CT scan contains 300+ slices and corresponding reports exceed 300 words. A standard 2D CLIP model processes slices independently, missing the 3D shape of a tumor or organ, while Merlin processes the entire volume at once to capture spatial continuity.
Key Novelty
Merlin: 3D-native Vision-Language Pretraining with Multi-Granularity Supervision
- Processes full 3D CT volumes natively rather than aggregating 2D slices, preserving volumetric spatial relationships
- Uses 'radiology report splitting' to align specific anatomical image regions with their corresponding text sections (e.g., matching liver voxels to 'liver: normal' text)
- Integrates structured EHR diagnosis codes as an additional supervision signal alongside unstructured text reports during pretraining
Architecture
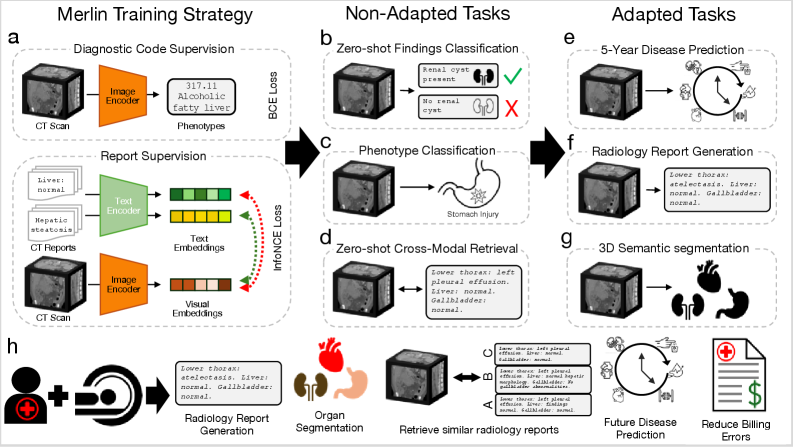
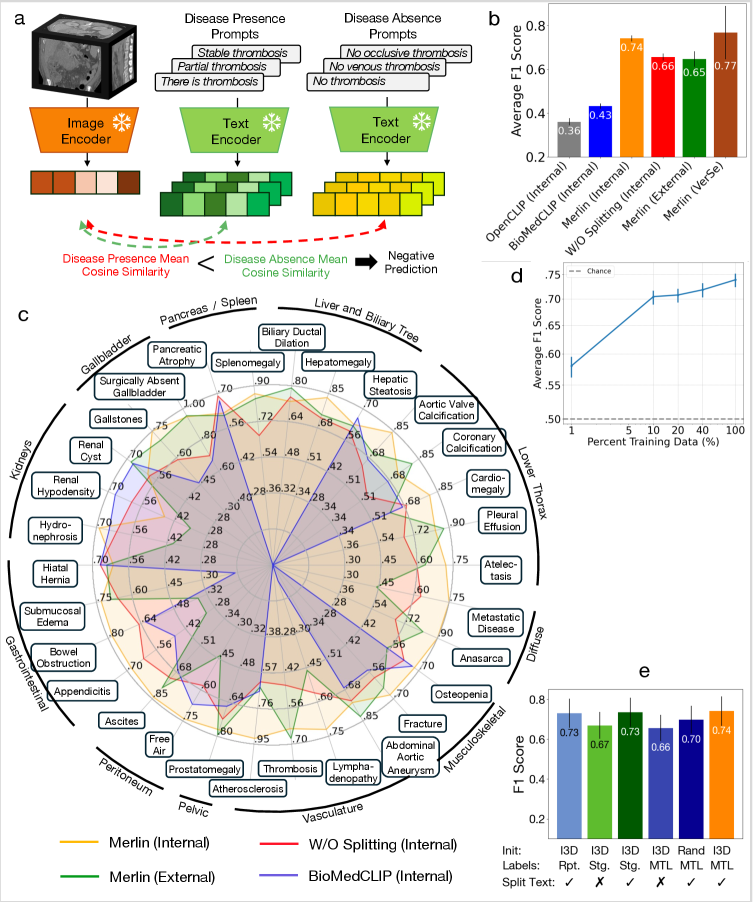
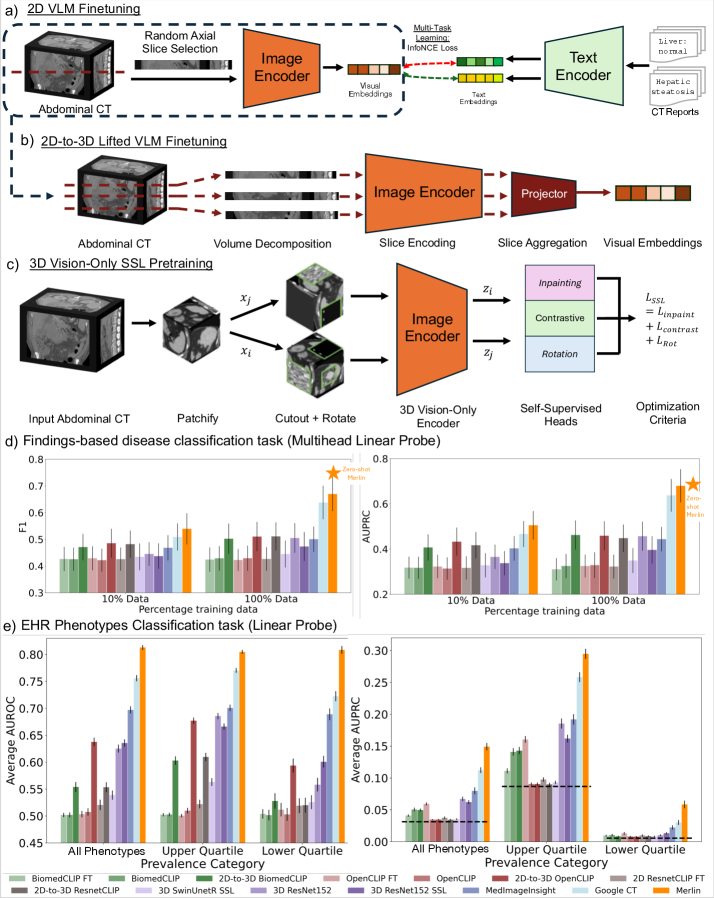
Overview of Merlin's training pipeline and downstream tasks.
Evaluation Highlights
- +16.0% improvement in F1 score (0.741 vs 0.641) for zero-shot findings classification compared to supervised training on the same data
- Outperforms state-of-the-art 2D-to-3D lifted VLMs (like BioMedCLIP) by 32.1% F1 on findings classification and 39.8% AUROC on phenotype classification
- Achieves equivalent segmentation performance to nnUNet using only 10% of training data, demonstrating high label efficiency
Breakthrough Assessment
9/10
Significant leap in medical AI by successfully scaling VLM pretraining to true 3D volumes with diverse supervision (text + EHR). Strong empirical results across many tasks and release of a large-scale dataset/model make it a major resource.