📝 Paper Summary
Remote Sensing Vision-Language Models
Multimodal Instruction Tuning
GeoChat adapts LLaVA-1.5 for remote sensing by fine-tuning on a newly created 318k multimodal instruction dataset, enabling unified object grounding, region-specific dialogue, and scene classification.
Core Problem
General-domain VLMs perform poorly on remote sensing imagery due to unique challenges like high resolution, diverse scales, and small objects, often hallucinating or failing to ground responses visually.
Why it matters:
- Standard VLMs provide inaccurate or fabricated information when querying spatial RS images.
- Existing RS methods (like classification-based VQA) lack open-ended conversation and instruction-following capabilities.
- Lack of domain-specific multimodal instruction data prevents models from aligning with user queries about satellite imagery.
Concrete Example:
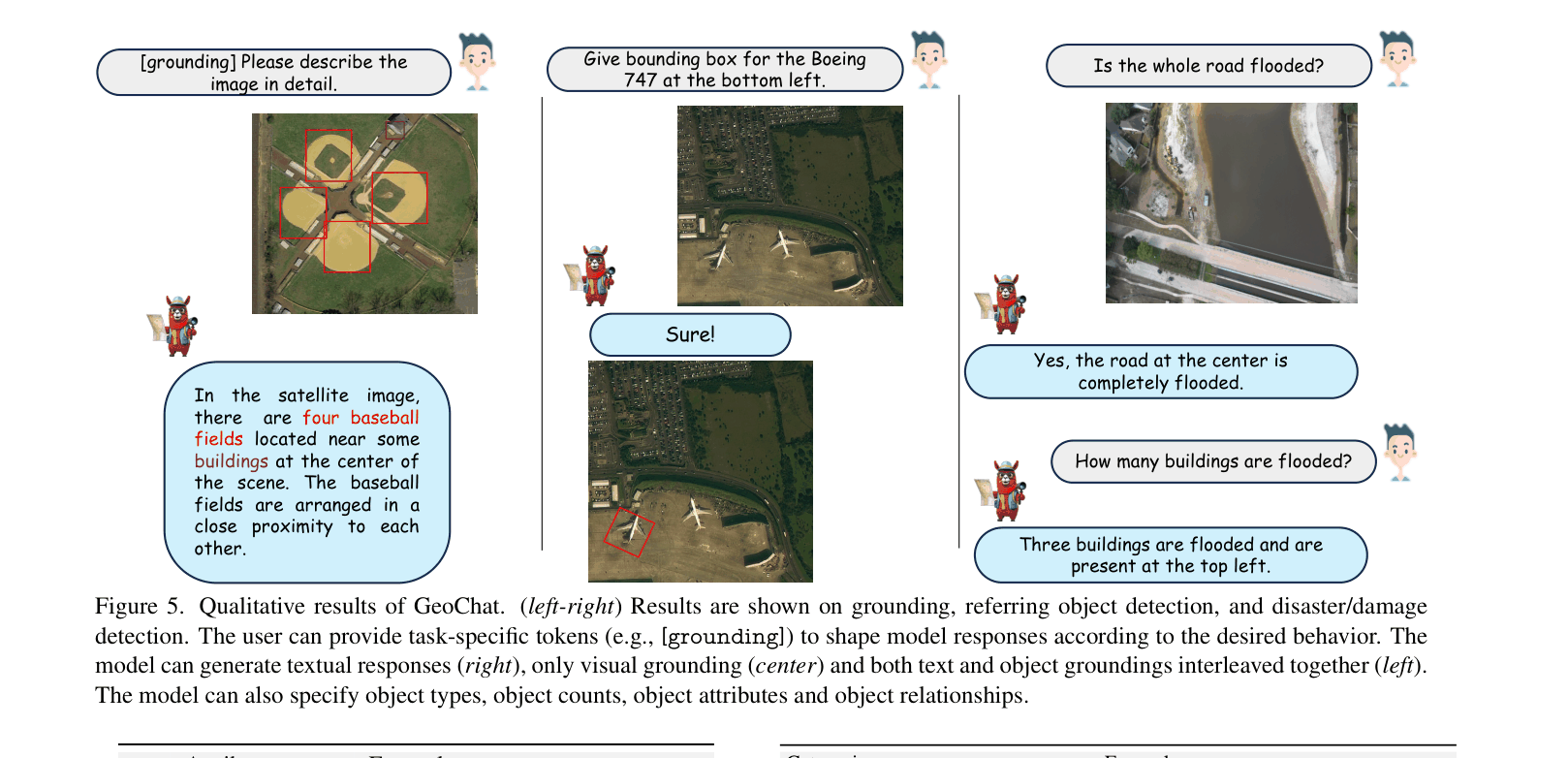
When asked 'How many tennis courts are visible?', a general VLM might miss small objects or hallucinate, whereas GeoChat correctly identifies and grounds '10 tennis courts' by leveraging high-resolution inputs and region-specific training.
Key Novelty
Unified Grounded Remote Sensing VLM
- Extends the LLaVA architecture with task-specific tokens (e.g., [grounding], [identify]) to switch between grounding, captioning, and conversation modes.
- Interpolates positional encodings to handle higher-resolution images (504x504), essential for detecting small objects in satellite imagery.
- Generates a massive domain-specific instruction dataset (318k pairs) by repurposing existing detection, classification, and VQA datasets into conversation formats.
Architecture
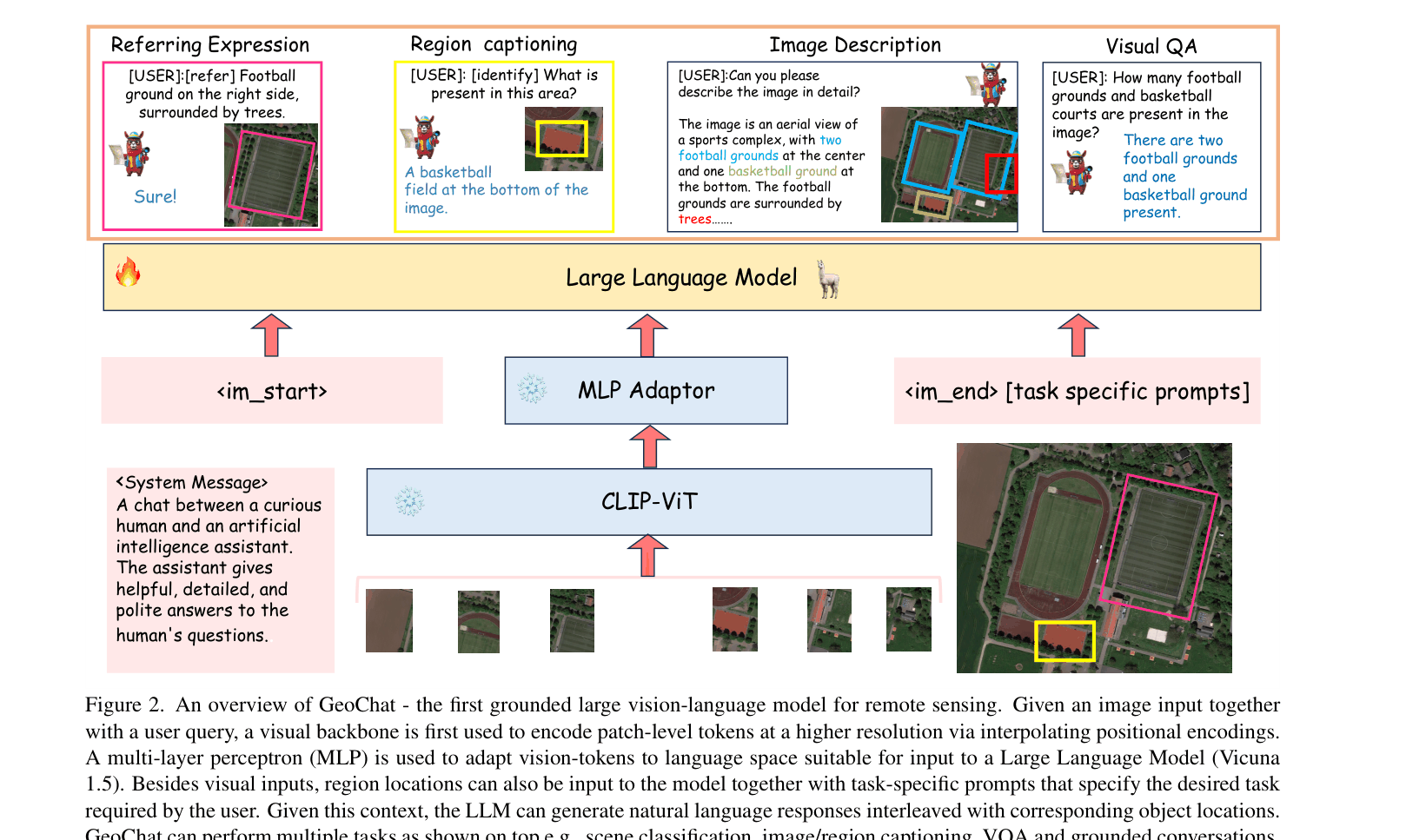
Overview of the GeoChat architecture and inference flow. It shows the Image Encoder, MLP Adaptor, and LLM components.
Evaluation Highlights
- Outperforms state-of-the-art RS-specialized models like RSGPT on the RSVQA-LRBEN dataset (94.00% vs 94.00% on rural/urban classification, competitive overall).
- Achieves robust zero-shot scene classification accuracy (84.43% on UCMerced), significantly outperforming general domain VLMs like LLaVA-1.5 (68.00%).
- Demonstrates superior region-level captioning capabilities compared to MiniGPT-v2, achieving a METEOR score of 83.9 vs 10.0.
Breakthrough Assessment
8/10
First VLM to unify conversation and visual grounding specifically for remote sensing. The creation of a large-scale instruction dataset fills a major gap, though the architecture is a direct adaptation of LLaVA.