📝 Paper Summary
Robot Manipulation
Spatial Reasoning
3D Vision
SoFar introduces 'Semantic Orientation'—language-defined object directions like 'handle'—and integrates a specialist orientation model (PointSO) with VLMs to enable precise 6-DoF robot manipulation without pre-defined templates.
Core Problem
Current Vision-Language Models (VLMs) and robot policies focus on object position but fail to understand fine-grained object orientation, making them unable to link language instructions to specific geometric alignments.
Why it matters:
- Tasks like plugging in a cord or uprighting a glass require precise 6-DoF alignment, not just location, which current models overlook
- Traditional methods rely on pre-defined templates or frames, which limits generalization to unseen objects and fails to ground orientation in natural language descriptions
- Translating open-vocabulary instructions (e.g., 'point the blade away') into vector rotations is a missing capability in foundation models
Concrete Example:
Inserting a pen into a holder requires aligning the pen tip with the holder's opening. A position-only model might place the pen near the holder but sideways or upside down, causing the task to fail.
Key Novelty
Semantic Orientation for Autonomous Robots (SoFar)
- Defines 'Semantic Orientation' as a unit vector derived from an object's geometry that aligns with a specific language description (e.g., 'cutting direction' of a knife) rather than a fixed coordinate frame.
- Introduces PointSO, a cross-modal 3D Transformer trained on a massive new dataset (OrienText300K), to predict these semantic vectors directly from point clouds and text.
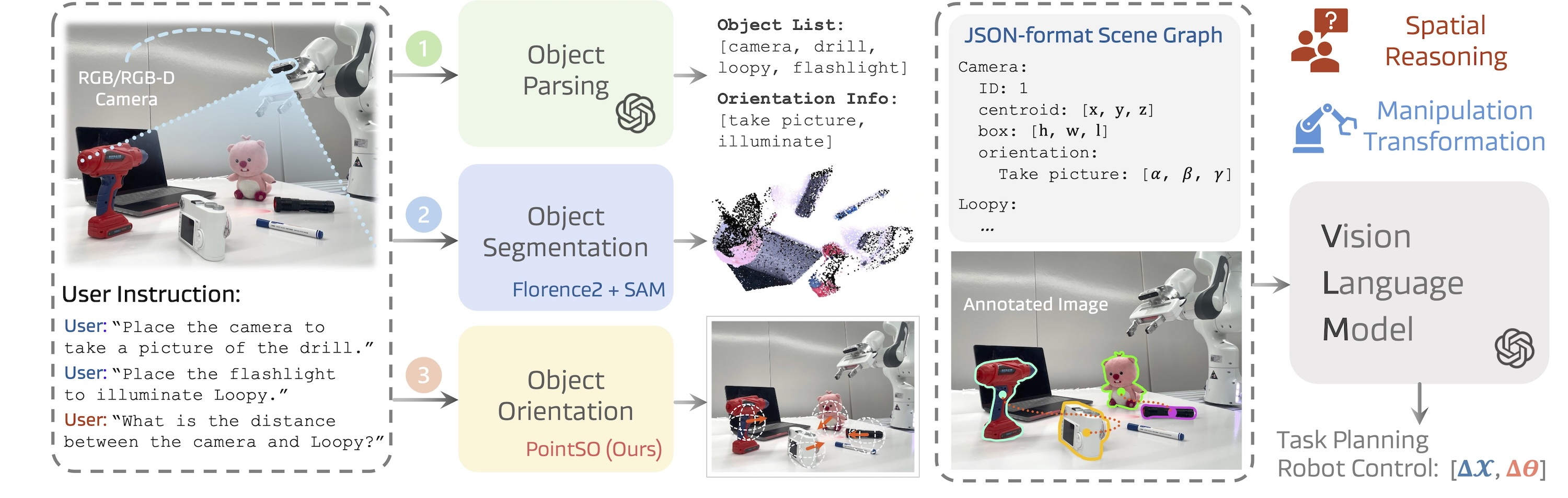
- Constructs a 6-DoF scene graph that explicitly encodes these orientation vectors, enabling a VLM to reason about and plan precise rotational alignments for manipulation.
Architecture
Overview of the SoFar framework pipeline, from input processing to robot execution.
Evaluation Highlights
- 74.9% zero-shot success rate on SimplerEnv manipulation tasks, outperforming models trained on robot data like Octo and OpenVLA
- 48.7% zero-shot success rate on Open6DOR (6-DoF rearrangement), significantly surpassing state-of-the-art VLMs
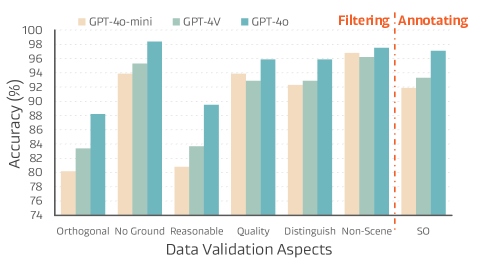
- 60.0% accuracy in predicting semantic orientations within a strict 5° error threshold on the OrienText300K validation set
Breakthrough Assessment
8/10
Ideally bridges high-level VLM reasoning with low-level geometric control by introducing a missing semantic primitive (orientation). Strong zero-shot results on established benchmarks.