📝 Paper Summary
Vision-Language Model (VLM) Architecture
Document Understanding
This paper provides a tutorial on building VLMs by analyzing architectural trade-offs and releases Idefics3-8B, a model significantly improved on document tasks via the massive new Docmatix dataset.
Core Problem
The VLM field lacks consensus on key design choices (architecture, data, training), and existing open datasets for document understanding are insufficient in scale.
Why it matters:
- Divergent design choices (e.g., fusing visual info via cross-attention vs. concatenation) are rarely ablated, making it difficult to assess performance and efficiency trade-offs
- Document understanding tasks require extensive OCR capabilities, but prior open datasets were too small to train robust models effectively
- Design decisions often lack justification in literature, hindering the community's ability to build efficient, high-performing pipelines
Concrete Example:
Current models like LLaVA concatenate visual tokens to text, while Llama 3-V uses interleaved cross-attention (like Flamingo). Without side-by-side analysis, it is unclear which approach yields better compute/data efficiency or text-only performance.
Key Novelty
Idefics3-8B and Docmatix Dataset
- Tutorial-style analysis of VLM components (architectures, data, training) to guide future model building
- Creation of Docmatix, a document understanding dataset 240 times larger than previous open equivalents, derived from PDF documents
- Release of Idefics3-8B, a VLM built on Llama 3 that simplifies the training pipeline while maximizing document processing capabilities
Architecture
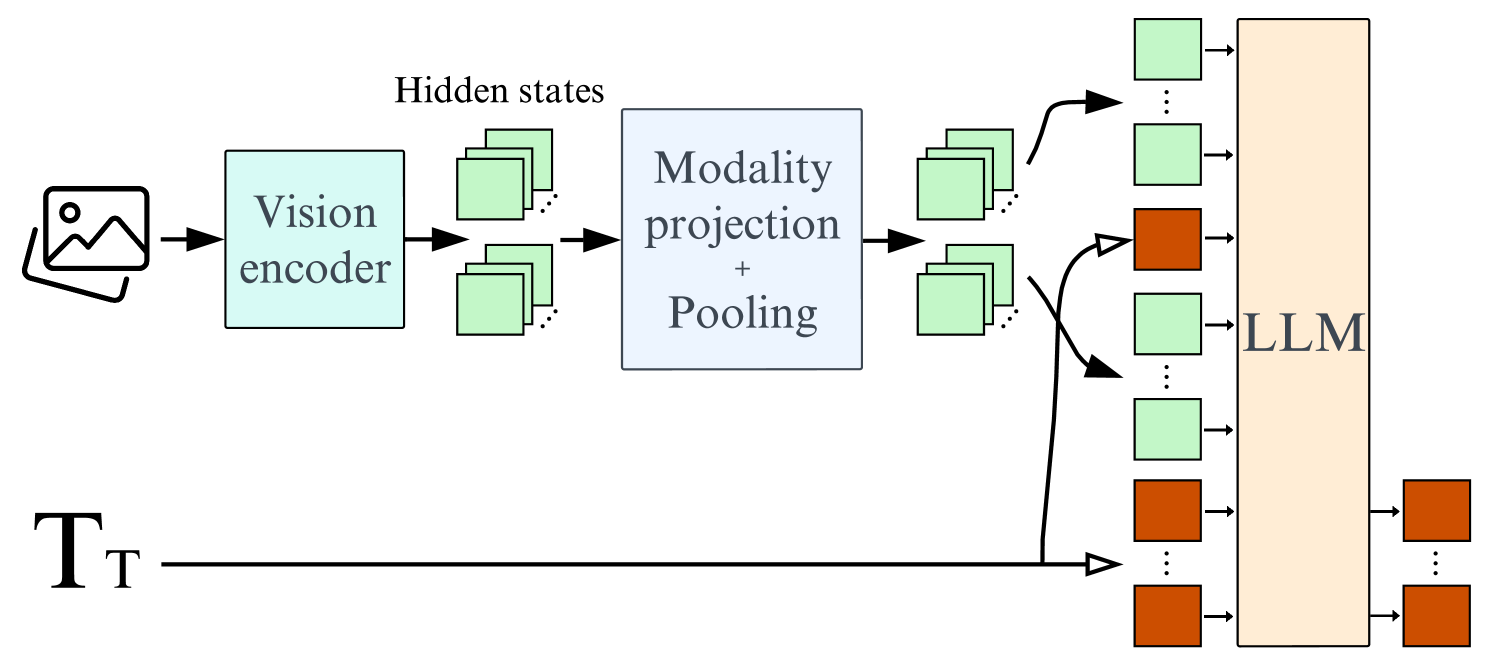
Highlights the components of the self-attention VLM architecture.
Evaluation Highlights
- +13.7 point improvement on DocVQA benchmark by Idefics3-8B compared to its predecessor Idefics2-8B
- Docmatix dataset scale: 2.4 million images and 9.5 million QA pairs derived from 1.3 million PDFs (240-fold increase over prior open datasets)
Breakthrough Assessment
8/10
While the architecture consolidates existing best practices rather than inventing new ones, the 240x scale-up of open document data (Docmatix) and the strong resulting performance improvement constitute a significant resource contribution.