📝 Paper Summary
Android device control
Multi-modal agents
DigiRL trains vision-language models to control Android devices by fine-tuning them on their own autonomous interactions using a scalable parallel environment and a specialized offline-to-online reinforcement learning algorithm.
Core Problem
Off-the-shelf vision-language models struggle with real-world device control because static training data fails to capture the stochasticity, non-stationarity, and dynamic nature of in-the-wild GUIs.
Why it matters:
- Static demonstrations become stale as apps update, leading to agents that cannot adapt to visual changes or recover from their own mistakes.
- Proprietary model wrappers (like GPT-4V with prompting) are slow, expensive, and limited by the base model's inability to reason about low-level pixel actions.
- Existing RL methods for device control are often too sample-inefficient or require simplified, deterministic environments that don't reflect real-world complexity.
Concrete Example:
When asked to 'Go to newegg.com and search for razer kraken', a model trained on static data might fail if a new pop-up ad appears or the search bar location changes, unable to recover because it never experienced these specific failures during training.
Key Novelty
Scalable Offline-to-Online RL for Device Control
- Builds a parallelized Android environment that runs up to 64 emulators simultaneously with a VLM-based autonomous evaluator to provide reward signals without human intervention.
- Uses a curriculum-based Advantage-Weighted Regression (AWR) approach that filters training data based on task difficulty (instruction-level value) and action quality (step-level value) to handle noisy, stochastic environments.
Architecture
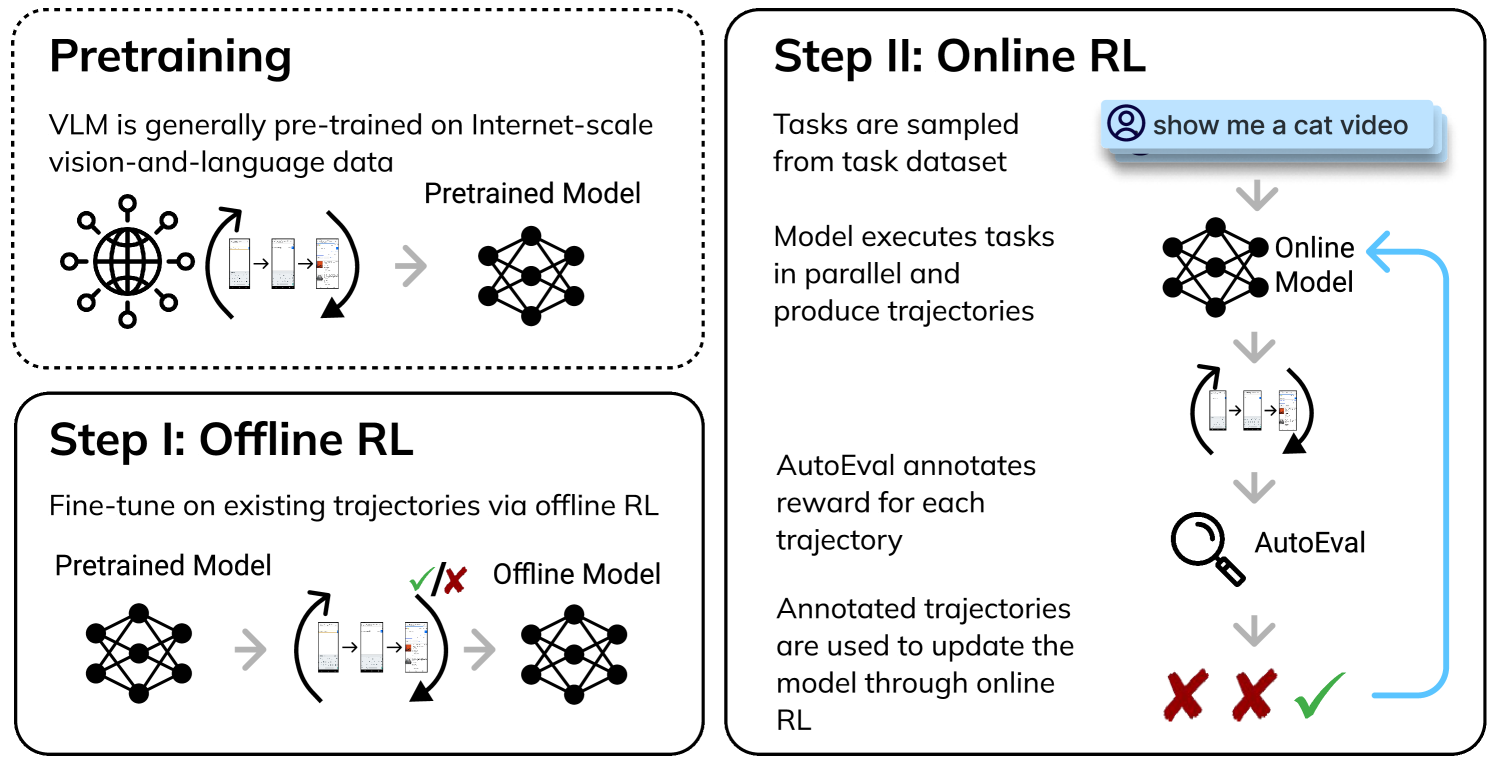
Overview of the DigiRL training pipeline, showing the two-stage process (Offline RL -> Online RL) and the parallelized environment.
Evaluation Highlights
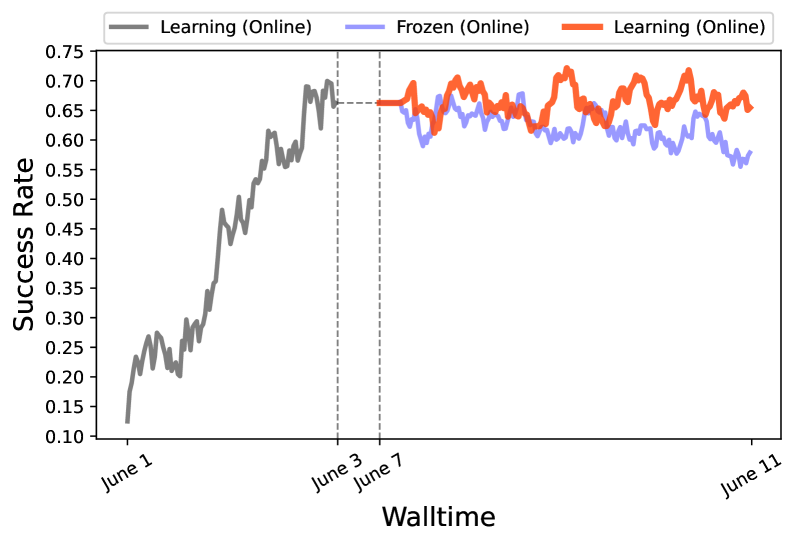
- Achieves 67.2% success rate on Android-in-the-Wild (AitW) tasks, a +49.5% absolute improvement over supervised fine-tuning (17.7%).
- Outperforms state-of-the-art 18B CogAgent (38.5%) and GPT-4V based AppAgent (8.3%) despite using a smaller 1.3B parameter model.
- Surpasses the best prior autonomous method (Filtered Behavior Cloning) by over 9% (57.8% vs 67.2%).
Breakthrough Assessment
9/10
Establishes a new SOTA for device control by successfully scaling autonomous offline-to-online RL, demonstrating that small models trained on self-experience can significantly outperform much larger proprietary models.