📝 Paper Summary
Vision-Language Models (VLMs)
Transfer Learning
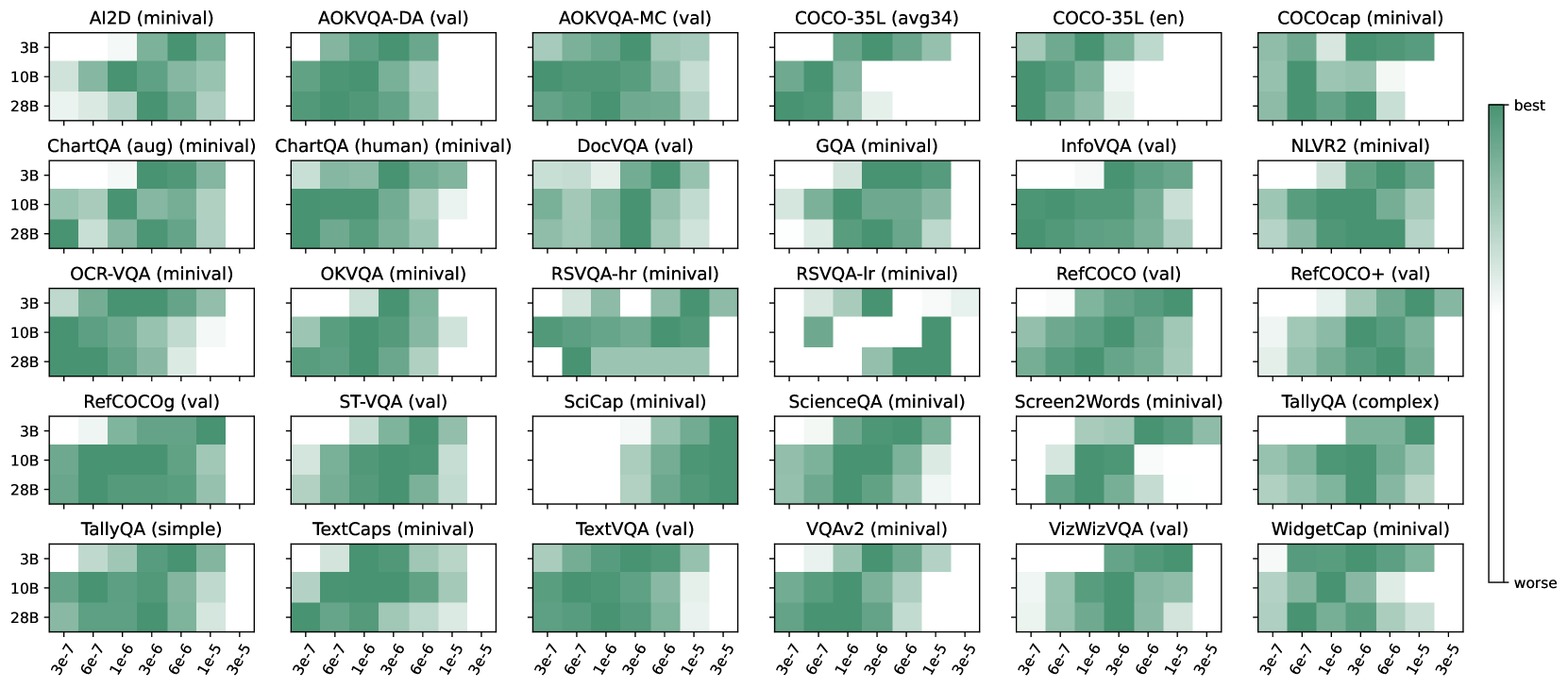
Model Scaling Analysis
PaliGemma 2 integrates the SigLIP vision encoder with Gemma 2 language models across varying sizes and resolutions to provide a versatile, open family of VLMs optimized for transfer learning.
Core Problem
Prior VLM research often studies scaling factors like image resolution and model size in isolation or uses disparate architectures, making it difficult to optimize compute for specific downstream tasks.
Why it matters:
- Different tasks require different resources; document understanding needs high resolution, while reasoning needs larger language models
- Existing open models often lack the versatility to handle niche domains (e.g., molecular graphs, music scores) without specialized architectural changes
- Practitioners need a controlled 'family' of models to trade off latency, compute, and performance effectively
Concrete Example:
In optical music recognition, a standard 224px resolution fails to capture fine staff lines, requiring 896px for low error rates. Conversely, spatial reasoning tasks benefit significantly from a larger 10B model but show little gain from increased resolution.
Key Novelty
PaliGemma 2 (Broad Scaling Analysis & Architecture Upgrade)
- Upgrades the language decoder to the Gemma 2 family (2B, 9B, 27B) while retaining the efficient SigLIP vision encoder, creating a consistent architecture across scales
- Employs a multi-stage training recipe that progressively increases resolution (up to 896px) and data complexity to prepare models for fine-grained transfer tasks
- Demonstrates that a general-purpose VLM interface can replace specialized architectures in niche domains like molecular recognition and radiography
Architecture
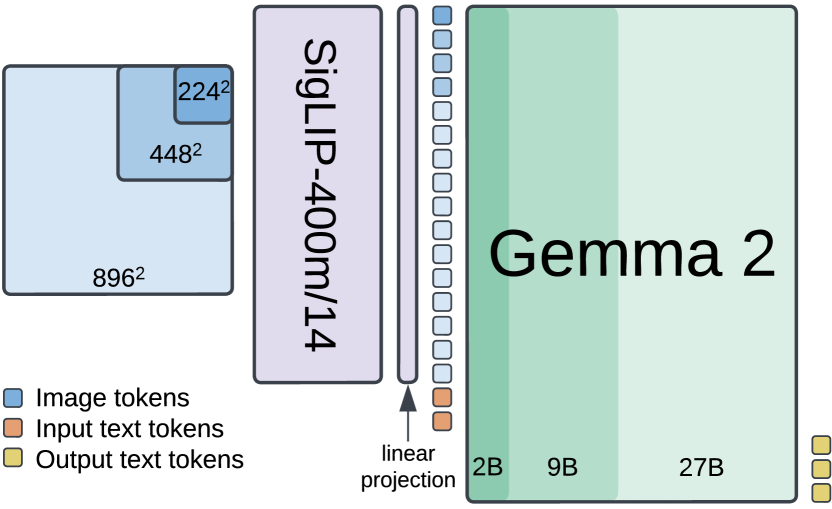
System architecture flow: Vision Encoder (SigLIP) -> Projection -> Concatenation with Text -> Language Model (Gemma 2) -> Autoregressive Output.
Evaluation Highlights
- +0.65 average score improvement on 30+ academic benchmarks for PaliGemma 2 3B (224px) compared to the original PaliGemma 3B
- State-of-the-art results on OCR benchmarks (ICDAR'15, Total-Text) and table recognition (PubTabNet, FinTabNet) by scaling resolution to 896px
- State-of-the-art RadGraph F1 score on MIMIC-CXR radiology report generation, outperforming baselines like R2GenGPT
Breakthrough Assessment
8/10
Provides a highly controlled, comprehensive study of VLM scaling while delivering SOTA performance on diverse, difficult specialized tasks (OCR, Chem, Med) using a unified generalist architecture.