📝 Paper Summary
Vision-Language-Action (VLA) Models
Embodied AI
Robot Manipulation
VLA-Adapter is a lightweight VLA framework that uses a Bridge Attention mechanism to selectively inject optimal vision-language features into a policy network, enabling state-of-the-art performance with a 0.5B model trained in just 8 hours.
Core Problem
Current VLA models rely on massive backbones (e.g., 7B+) and extensive robotic pre-training, leading to high computational costs, slow inference, and inefficient bridging between perception and action spaces.
Why it matters:
- High training costs and VRAM requirements prevent widespread deployment and experimentation on consumer hardware
- Slow inference speeds (low throughput) limit real-time robotic control capabilities
- Existing methods inefficiently utilize vision-language features, either losing fine-grained details (deep layers) or missing semantic context (shallow layers)
Concrete Example:
A standard VLA model like OpenVLA-7B requires large-scale pre-training data and runs slowly (e.g., ~6Hz), whereas VLA-Adapter achieves comparable results using a tiny 0.5B backbone with no robotic pre-training, training in just 8 hours.
Key Novelty
VLA-Adapter with Bridge Attention
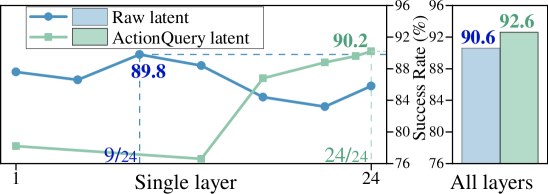
- Identifies that middle-layer VLM features are best for raw perception (rich multimodal details) while deep-layer features are best for ActionQueries (high-level semantics)
- Introduces a 'Bridge Attention' module that autonomously injects these optimal conditions into the action policy using a learnable gating mechanism
- Decouples the heavy VLM backbone from the lightweight Policy network, allowing efficient training from scratch without fine-tuning the entire VLM
Architecture
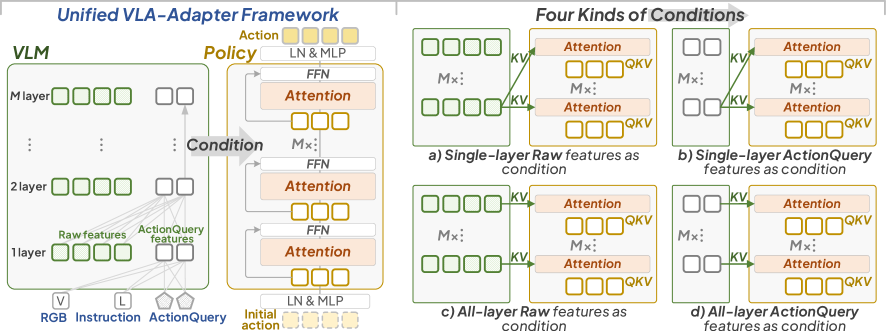
The overall VLA-Adapter framework and the specific Policy architecture. It illustrates how images and instructions are processed by the VLM to produce Raw and ActionQuery latents, which are then fed into the Bridge Attention Policy.
Evaluation Highlights
- Trains a full VLA model in just 8 hours on a single consumer-grade GPU, significantly lowering the barrier to entry compared to models requiring clusters
- Achieves high performance on LIBERO benchmarks using only a 0.5B-parameter backbone (Qwen2.5-0.5B), drastically smaller than the typical 7B baselines
- Offers the fastest inference speed reported to date among VLA models, addressing the bottleneck of real-time control
Breakthrough Assessment
8/10
Significant for democratizing VLA research by reducing training time to 8 hours on a single GPU and showing that tiny 0.5B models can compete with 7B models via better architectural design.