📝 Paper Summary
GUI Agents
Visual Grounding
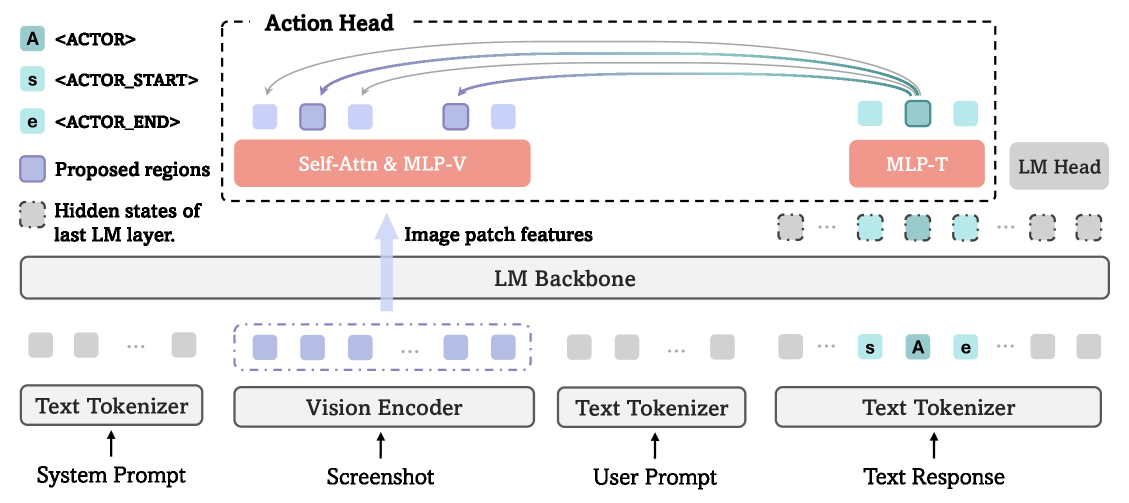
GUI-Actor replaces text-based coordinate generation with an attention-based action head that aligns a special actor token directly to visual patches, mimicking human look-and-click behavior.
Core Problem
Existing GUI agents treat grounding as coordinate generation (predicting text tokens like 'x=0.12'), which creates a mismatch between coarse visual features and dense pixel coordinates.
Why it matters:
- Spatial-semantic alignment is weak because VLMs must implicitly map visual inputs to numeric text without explicit spatial supervision
- Supervision is ambiguous; single-point training data penalizes valid clicks within a button that don't match the exact ground truth pixel
- Granularity mismatch exists between Vision Transformer (ViT) patch-level features and high-resolution screen coordinates, undermining generalization to new layouts
Concrete Example:
When asking an agent to 'click the submit button', a coordinate-based model might be penalized for predicting 'x=0.51' if the ground truth is 'x=0.50', even though both are valid clicks within the button.
Key Novelty
Coordinate-Free Grounding via Action Attention
- Introduces a special <ACTOR> token that acts as a contextual anchor, aggregating instructions and visual features
- Uses an attention mechanism to directly map this anchor to relevant visual patches on the screenshot, bypassing numeric coordinate generation entirely
- Employs multi-patch supervision where all patches overlapping the target element are positive, tolerating spatial ambiguity better than single-point labels
Architecture
The GUI-Actor pipeline contrasting coordinate generation with attention-based grounding
Evaluation Highlights
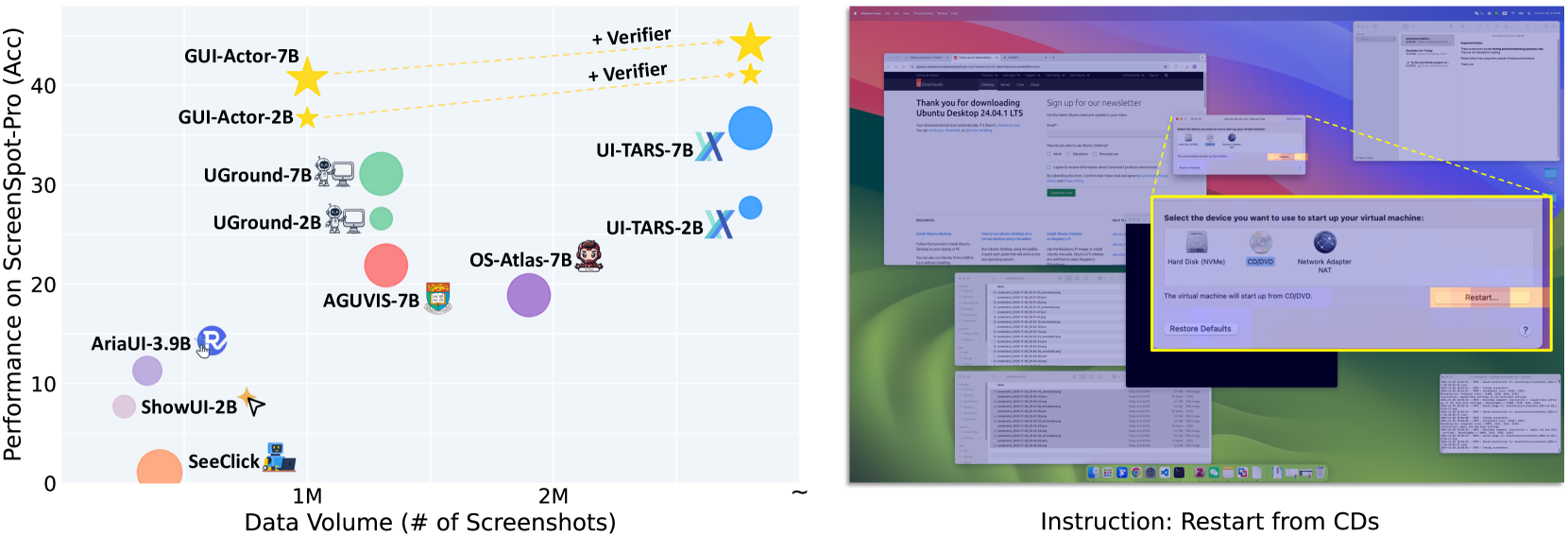
- GUI-Actor-7B (Qwen2.5-VL) achieves a score of 44.6 on ScreenSpot-Pro, significantly outperforming the much larger UI-TARS-72B (38.1)
- With Qwen2-VL backbone, GUI-Actor-7B scores 40.7 on ScreenSpot-Pro, surpassing state-of-the-art baselines with fewer parameters
- Fine-tuning only the 100M-parameter action head (while freezing the backbone) yields performance comparable to full fine-tuning
Breakthrough Assessment
8/10
Effective shift from the dominant coordinate-regression paradigm to a more 'native' visual attention approach. Achieves SOTA with significantly smaller models (7B vs 72B) and improved generalization.