📝 Paper Summary
3D Scene Understanding
Vision-Language Models (VLMs)
GPT4Scene enables Vision-Language Models to understand 3D indoor scenes from video by generating a global Bird's Eye View and overlaying consistent object markers across temporal frames.
Core Problem
Standard Vision-Language Models fail to understand 3D scenes from video because they lack a global spatial representation and cannot maintain object correspondence across changing local frames.
Why it matters:
- Current VLMs are excellent at 2D tasks but struggle with spatial comprehension required for embodied intelligence and robotics
- Existing 3D solutions rely on point clouds, which are computationally heavy and difficult to align with textual pre-training data compared to pure vision approaches
Concrete Example:
When a VLM views a video of a room and is asked 'Where is the black chair?', it may see the chair in one frame and a table in another, but fails to understand their relative spatial position or that they exist in the same 3D layout without explicit global linking.
Key Novelty
Visual Prompting with Global-Local Alignment
- Constructs a 3D Bird's Eye View (BEV) image from video to provide the VLM with a single, holistic map of the scene's layout (Global Information)
- Overlays Spatial-Temporal Object markers (STO-markers)—consistent ID tags—onto both the BEV map and individual video frames, forcing the model to link local observations to the global map
Architecture
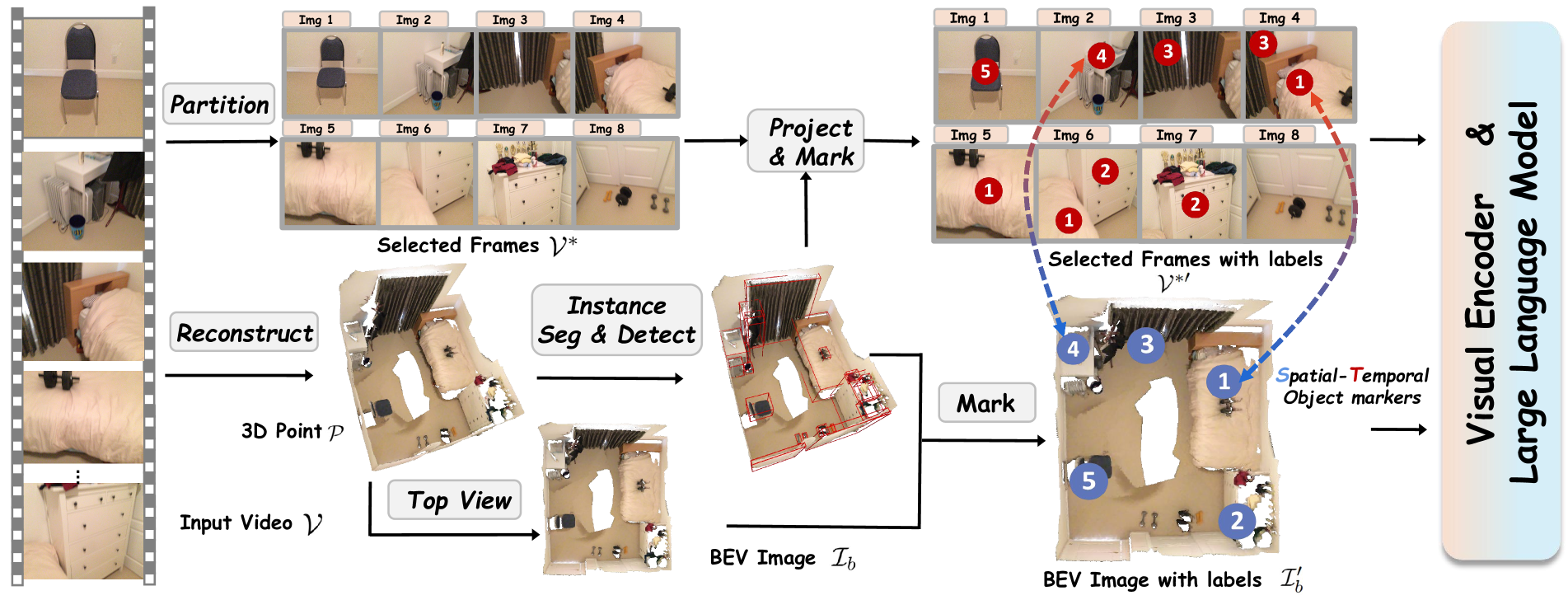
Overview of the GPT4Scene framework showing data flow from video to VLM.
Evaluation Highlights
- Fine-tuned Qwen2-VL-7B achieves 60.7 EM-1 on SQA3D, surpassing the previous state-of-the-art Chat-Scene (54.6) by 11.0%
- Achieves a 48% relative improvement (40.7 -> 60.7) on SQA3D compared to the base Qwen2-VL-7B model
- Outperforms Chat-Scene on Multi3DRef (Visual Grounding) by 13.0% (57.1 -> 64.5)
Breakthrough Assessment
8/10
Significantly outperforms specialized point-cloud-based methods using a pure vision approach. The finding that markers improve 'intrinsic' 3D understanding even when removed at inference is particularly novel.