📝 Paper Summary
Vision-Language-Action (VLA) Models
Robotic Manipulation
CogACT decouples high-level reasoning from low-level control by using a VLM to generate a 'cognition feature' that conditions a specialized, large-scale diffusion transformer for precise action sequence generation.
Core Problem
Existing VLAs (like RT-2 and OpenVLA) force continuous, high-frequency robot actions into discrete language tokens or simple regression heads, limiting precision and failing to capture the multimodal, probabilistic nature of physical motion.
Why it matters:
- Discrete tokenization designed for text is suboptimal for high-dimensional, continuous motor control
- Simple regression averages across valid modes (e.g., going left vs. right around an obstacle), leading to invalid 'mean' trajectories
- Current methods struggle with precision and smoothness, evidenced by low success rates in real-world manipulation tasks
Concrete Example:
When a robot attempts to grasp a mug, there may be multiple valid trajectories. A standard regression VLA might average these into a shaky, invalid path. A token-based VLA might coarsely quantize the movement, losing fine motor control. CogACT's diffusion head models the full distribution of valid trajectories.
Key Novelty
Componentized Cognition-Action Architecture
- Separates the 'brain' (VLM for reasoning) from the 'cerebellum' (Diffusion Transformer for motor control) unlike unified token-in-token-out models
- Uses a learnable 'cognition token' in the VLM to extract a compressed semantic instruction that conditions the action generation module
- Introduces a 'large' specialized action module (up to 300M parameters) rather than a small projection head, finding that scaling this module significantly improves performance
Architecture
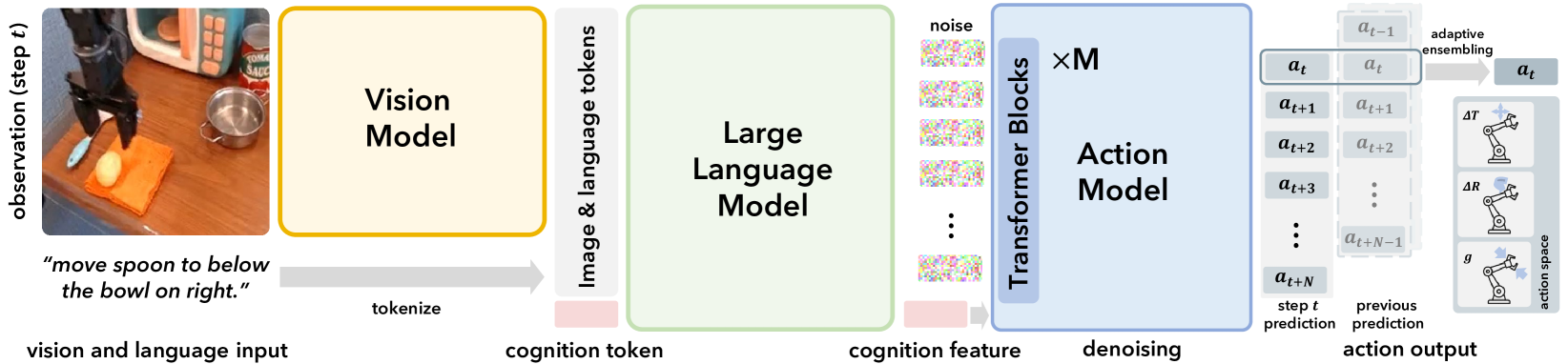
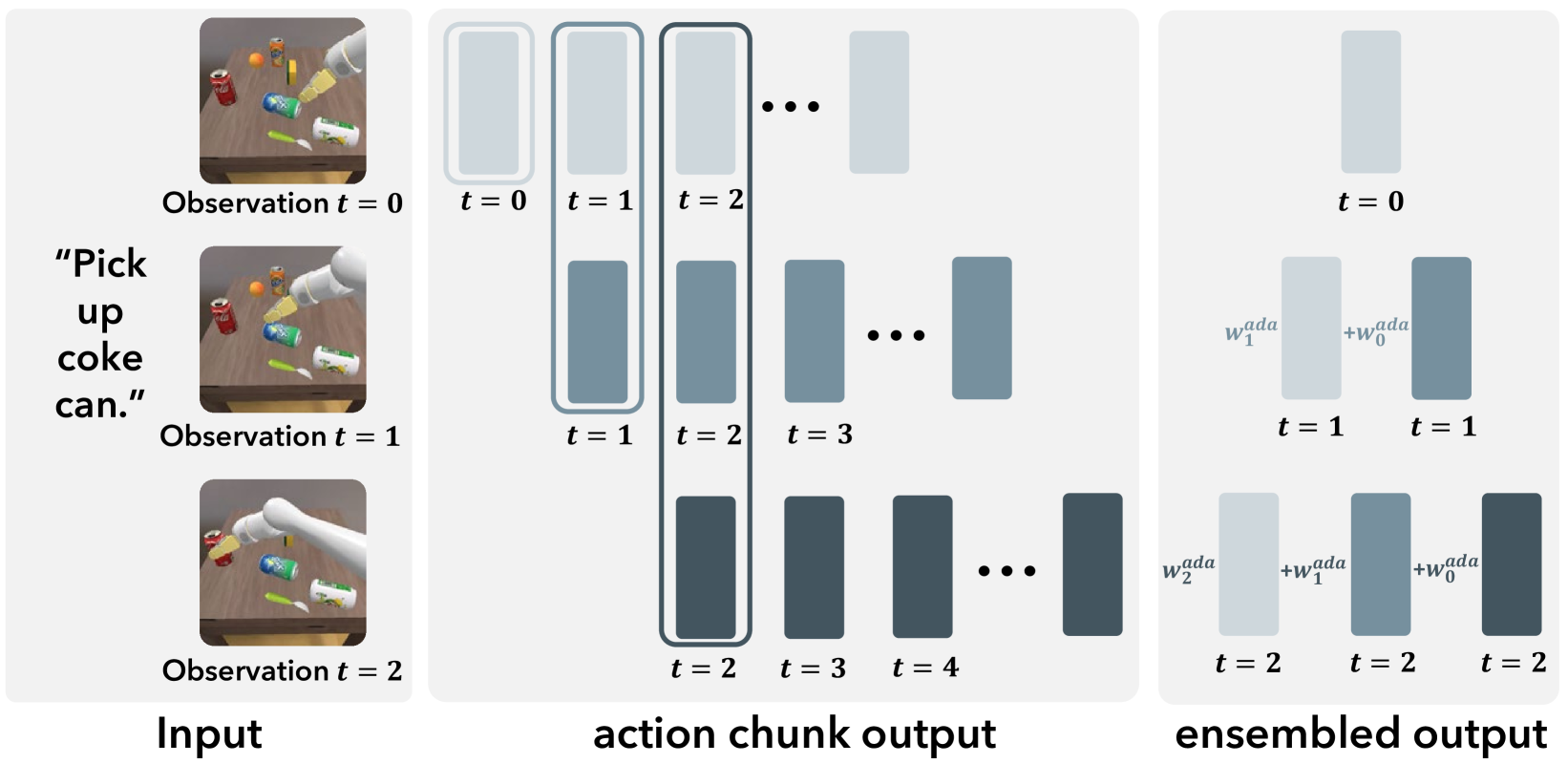
The complete CogACT pipeline showing the flow from Vision/Language inputs to Action outputs.
Evaluation Highlights
- Surpasses OpenVLA (7B) by over 35% success rate in simulated evaluations
- Outperforms OpenVLA (7B) by 55% success rate in real-world robot experiments
- Exceeds the performance of the significantly larger RT-2-X (55B) by 18% absolute success rate in simulation
Breakthrough Assessment
8/10
Strong empirical results (+55% real-world improvement) and a logical architectural shift (decoupling cognition/action) that addresses a fundamental limitation of treating actions as text tokens.