📊 Experiments & Results
Evaluation Setup
Evaluation on olmOCR-Bench, a suite of unit-tests for PDF extraction.
Benchmarks:
- olmOCR-Bench (PDF Content Extraction & Linearization) [New]
Metrics:
- Percentage of unit tests passed (Pass Rate)
- Cost per million pages ($)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Cost analysis demonstrates extreme efficiency improvements over using proprietary models for large-scale processing. | ||||
| N/A (Cost Analysis) | Cost per 1M pages ($) | 6240 | 176 | -6064 |
| N/A | Training Pages | 0 | 260000 | +260000 |
| olmOCR-Bench | Test Cases | 0 | 7010 | +7010 |
Experiment Figures
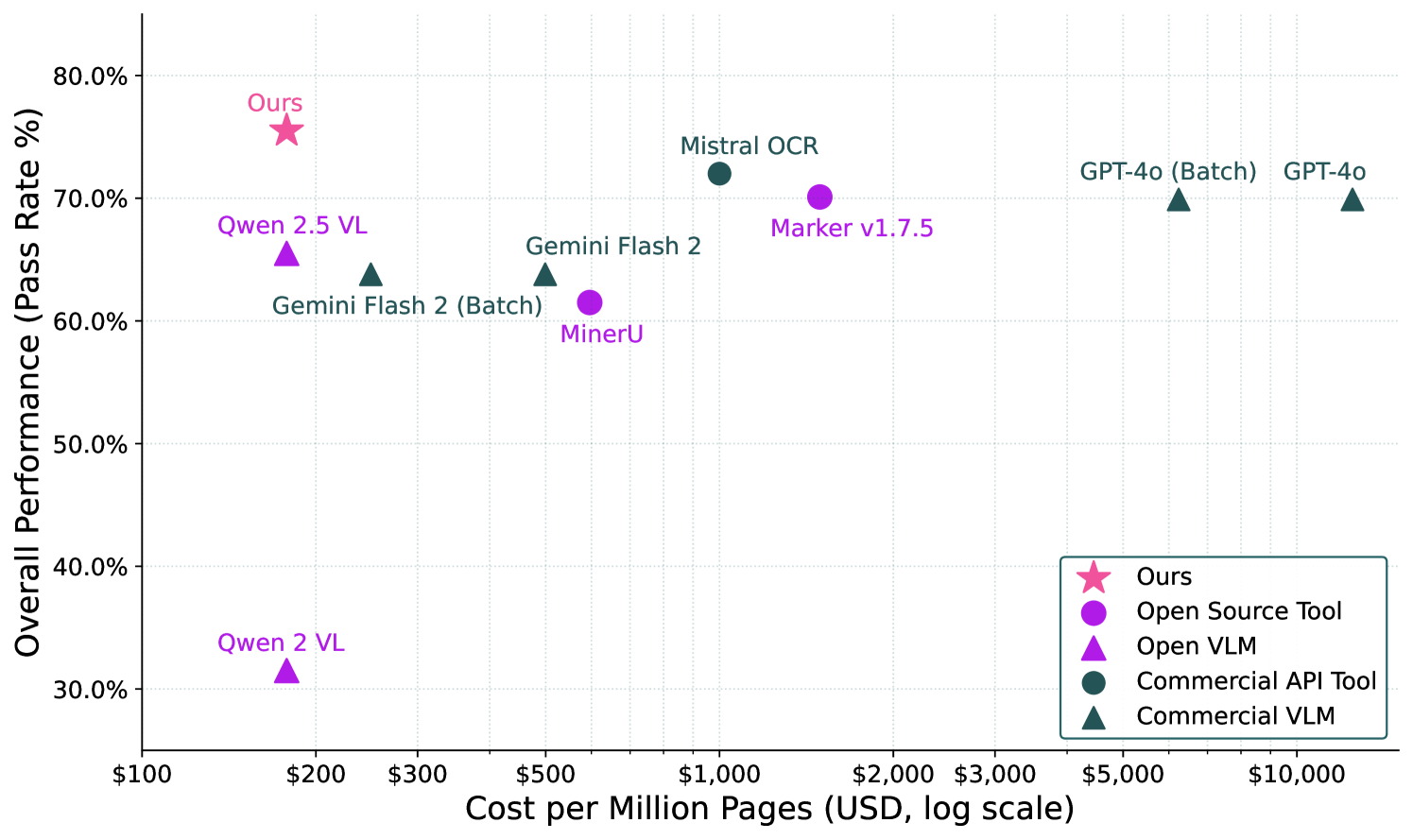
Illustration of raw PDF internal storage vs. logical structure
Main Takeaways
- olmOCR achieves state-of-the-art performance on the proposed benchmark, outperforming general purpose VLMs like GPT-4o and Qwen-2.5-VL (quantitative accuracy scores not provided in text snippet).
- The 'document-anchoring' technique (injecting raw PDF text hints) measurably improves generation quality compared to vision-only approaches.
- Training on linearized PDF data (olmOCR-peS2o) leads to observable downstream improvements in language model pretraining performance compared to baselines.
- Cost reduction allows for processing typically inaccessible data scales (trillions of tokens) within reasonable academic/research budgets.