📝 Paper Summary
Vision-Language Model Architecture
Multimodal Pre-training
The authors identify that fully autoregressive architectures with unfrozen backbones outperform cross-attention approaches, leading to Idefics2, an 8B parameter model achieving state-of-the-art performance in its size class.
Core Problem
Critical design decisions for Vision-Language Models (VLMs)—such as architecture type, connector design, and training stability—are often adopted without experimental justification, hindering the community's understanding of what truly drives performance.
Why it matters:
- Disparate design choices (e.g., cross-attention vs. concatenation) make it difficult to attribute performance gains to specific components
- Standard practices like resizing images to fixed squares distort aspect ratios, hurting performance on tasks involving text reading or fine details
- Inefficient architectures result in excessively long visual token sequences, increasing compute costs and limiting context windows
Concrete Example:
Standard VLMs often resize document images to low-resolution squares, making text unreadable. Idefics2 preserves the original aspect ratio and splits the image into sub-crops (e.g., 4 crops + original), allowing the model to read dense text in scanned PDFs where prior models failed.
Key Novelty
Idefics2 (Optimized Fully Autoregressive VLM)
- Systematic ablation revealing that fully autoregressive architectures (concatenating visual tokens to text) outperform cross-attention architectures only when the pre-trained backbones are unfrozen (via LoRA)
- Adoption of a 'split-and-crop' strategy where images are decomposed into sub-images to boost resolution for OCR tasks without altering the model signature
- Use of learned pooling (Perceiver Resampler) to drastically reduce visual token count (729 to 64) while improving downstream performance
Architecture
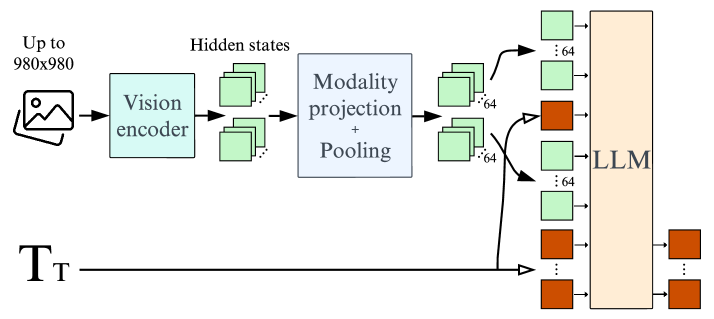
Illustration of the fully-autoregressive architecture used in Idefics2.
Evaluation Highlights
- +12.9 points average improvement across 4 benchmarks (VQAv2, TextVQA, OKVQA, COCO) when unfreezing backbones in a fully autoregressive architecture compared to freezing them
- Perceiver Resampler pooling improves performance by +8.5 points while reducing visual tokens per image from 729 to 64 compared to no pooling
- Replacing LLaMA-1-7B with Mistral-7B yields a +5.1 point boost; replacing CLIP-ViT-H with SigLIP-SO400M yields a +3.3 point boost
Breakthrough Assessment
8/10
Provides much-needed experimental clarity on VLM design choices (architecture trade-offs, freezing vs. unfreezing) and releases a strong 8B open model (Idefics2) that rivals much larger closed models.