📝 Paper Summary
Vision-Language Models (VLMs)
Chain-of-Thought Reasoning
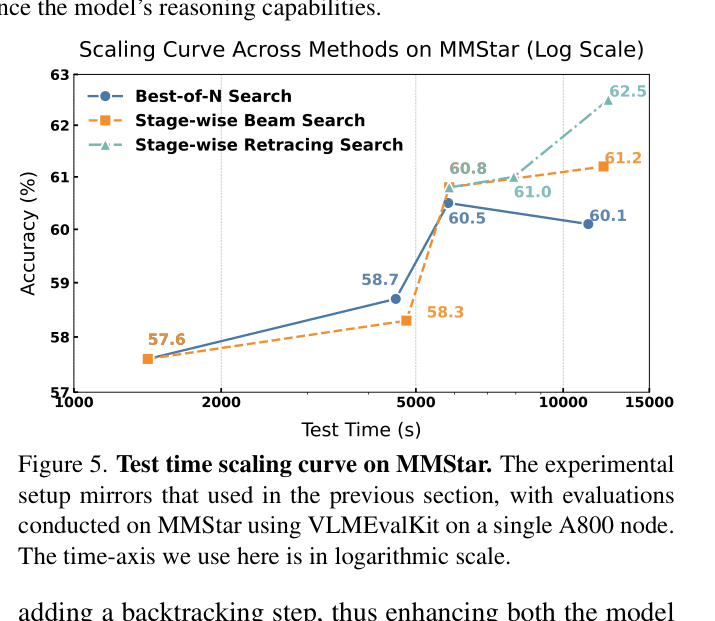
Test-Time Scaling
LLaVA-CoT enforces a four-stage structured reasoning process in VLMs and uses a test-time backtracking search to self-correct errors during inference.
Core Problem
Current Vision-Language Models struggle with systematic reasoning, often hallucinating or jumping to premature conclusions without first organizing visual information or logical steps.
Why it matters:
- Direct-response models lack the structured thought process needed for complex tasks like math or scientific reasoning
- Existing Chain-of-Thought (CoT) implementations in VLMs are prone to unrecoverable errors once a flawed reasoning path begins
- Smaller open-source models typically lag significantly behind large proprietary models (like GPT-4o) in reasoning-intensive benchmarks
Concrete Example:
When asked to 'Subtract all tiny shiny balls and purple objects' from a group, a base model immediately gives a wrong number. LLaVA-CoT first summarizes the task, captions the image (identifying specific shapes/colors), counts the total, identifies the target subsets, and then performs the subtraction to reach the correct answer.
Key Novelty
Stage-Wise Retracing Search (SWIRES) with Structured Generation
- Decomposes reasoning into four explicit, tag-delimited stages: Summary (plan), Caption (observe), Reasoning (analyze), and Conclusion (answer)
- Implements a test-time search strategy that doesn't just beam search forward but 'backtracks' to regenerate previous stages if the current stage's output is low-quality
Architecture
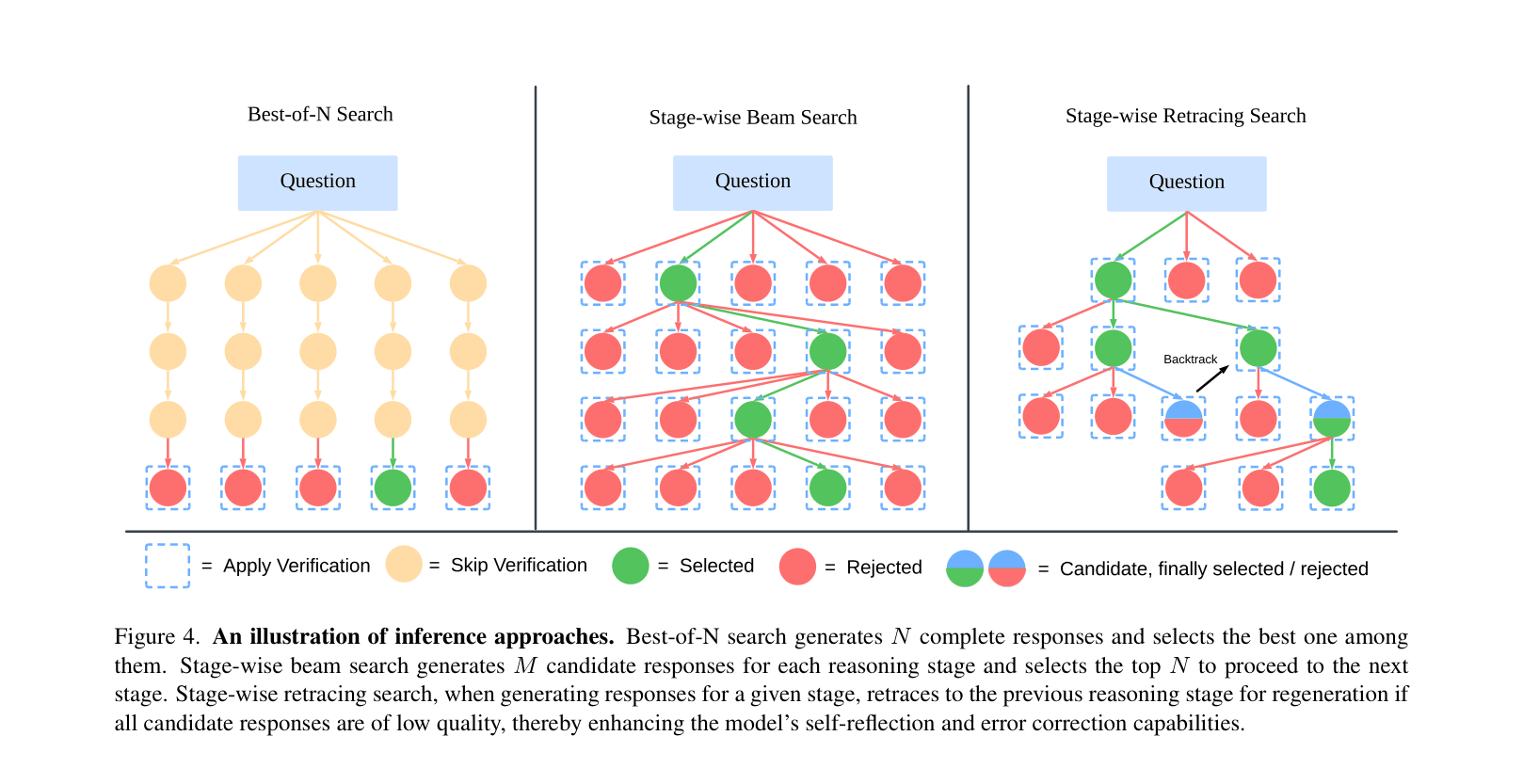
Comparison of inference search strategies: Best-of-N, Stage-wise Beam Search, and Stage-wise Retracing Search (SWIRES).
Evaluation Highlights
- Outperforms the base model (Llama-3.2-11B-Vision-Instruct) by +9.4% on average across 6 multimodal reasoning benchmarks using test-time scaling
- Surpasses larger open-source models (Llama-3.2-90B-Vision-Instruct) and closed-source models (GPT-4o-mini, Gemini-1.5-Pro) on average benchmark scores
- Scaling inference time via stage-wise retracing yields continuous performance gains, whereas traditional best-of-N search plateaus
Breakthrough Assessment
8/10
Significant for demonstrating that structured reasoning + inference-time search allows an 11B model to beat 90B and proprietary models. The 'retracing' mechanism effectively brings 'system 2' thinking to VLMs.