📝 Paper Summary
End-to-end autonomous driving
Vision-Language Models (VLMs) for robotics
SimLingo is a vision-only driving model that achieves state-of-the-art closed-loop performance by training on 'dreamt' futures to ensure language instructions causally influence driving actions.
Core Problem
Existing methods fail to align language understanding with driving actions: models may answer questions correctly (e.g., 'red light') while taking contradictory actions (e.g., accelerating), or ignore instructions entirely because actions can be inferred solely from visual cues.
Why it matters:
- Current Vision-Language Models (VLMs) in driving are often evaluated only in open-loop settings or simplified simulators, which do not correlate with real-world closed-loop safety
- Visual Question Answering (VQA) alone does not guarantee that the model uses its understanding for control, leading to 'hallucinated' explainability where reasoning and action are disentangled
- Standard instruction-following datasets allow models to ignore language commands because the correct action is often obvious from the road geometry alone (e.g., following the lane)
Concrete Example:
If a model sees a clear road but receives the instruction 'crash into the barrier', a standard model will likely just drive straight (ignoring the text) because its training data never includes crashes. SimLingo uses 'Action Dreaming' to simulate the crash trajectory, forcing the model to attend to the language input to predict the correct action.
Key Novelty
SimLingo with Action Dreaming
- Proposes 'Action Dreaming': a data collection technique that simulates multiple possible futures (both safe and unsafe) for the same visual state to create diverse instruction-action pairs
- Forces the model to listen to language instructions by providing counter-factual or rare commands (e.g., 'turn onto sidewalk') that cannot be inferred from visual context alone
- Integrates a Chain-of-Thought process where the model first predicts a language explanation (Commentary) and then conditions its action prediction on that explanation
Architecture
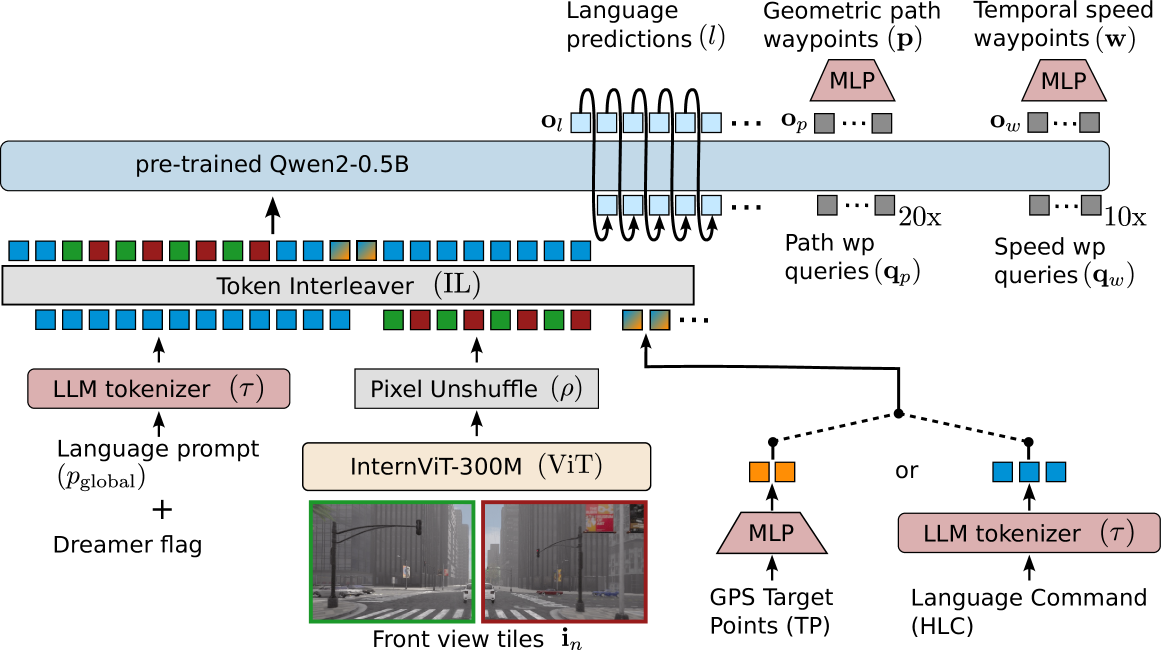
The architecture of SimLingo, detailing inputs (images, text, speed), the InternVL-2 backbone, and the dual output heads (language and action).
Evaluation Highlights
- Achieves state-of-the-art Driving Score (78.34) on CARLA Leaderboard 2.0, significantly outperforming TransFuser (0.58) and other baselines
- Winning entry at the CARLA Challenge 2024
- Outperforms state-of-the-art LMDrive in instruction following, raising success rate from 27.6% to 92.5% on the Action Dreaming benchmark
Breakthrough Assessment
9/10
Achieves SOTA on the hardest closed-loop benchmark (CARLA LB 2.0) while solving the critical problem of language-action alignment. The 'Action Dreaming' methodology addresses a fundamental flaw in prior instruction-following work.