📝 Paper Summary
Robotic Manipulation
Vision-Language-Action (VLA) Models
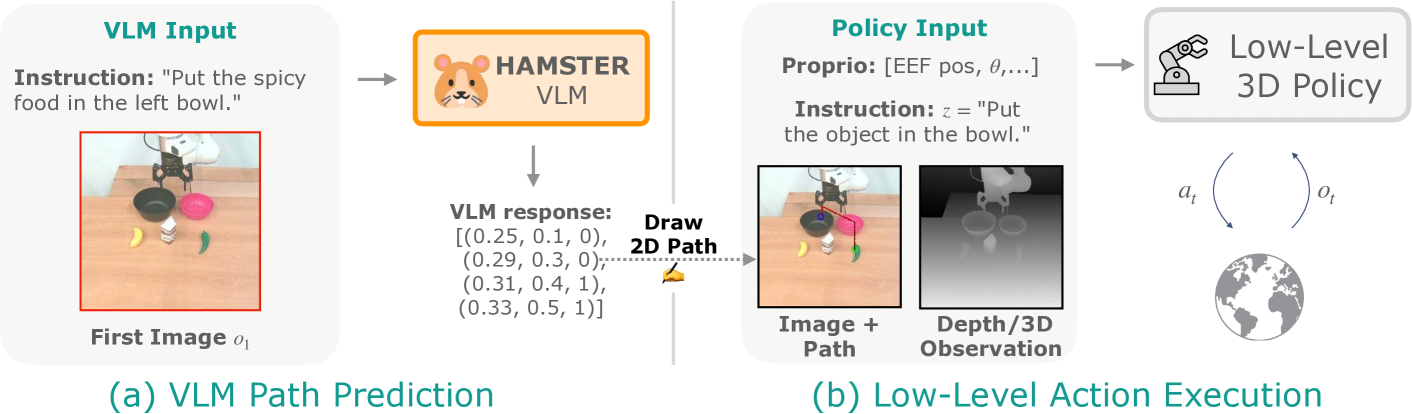
HAMSTER decouples manipulation into high-level VLM-based 2D path planning trained on cheap off-domain data and low-level 3D policies that execute these paths with high-frequency control.
Core Problem
Monolithic VLA models require expensive, scarce on-robot data and struggle with dexterity due to low inference frequency, while small specialist policies fail to generalize to new semantic instructions or visual variations.
Why it matters:
- Collecting end-to-end on-robot data (observation-action pairs) is prohibitively expensive and currently insufficient for open-world generalization
- Monolithic models cannot easily leverage abundant 'off-domain' data (simulations, human videos) because they require precise robot actions which are absent or mismatched in such data
- Existing small policies are brittle to drastic environmental changes, limiting their utility in diverse real-world scenarios
Concrete Example:
A standard robot policy trained on tabletop data might fail if the table color changes or the object description is semantically complex (e.g., 'the toy that looks like a cat'), whereas a VLM can understand the semantics but lacks the 3D precision to grasp it directly.
Key Novelty
Hierarchical Action Models with SeparaTEd Path Representations (HAMSTER)
- Decomposes the control loop: A large VLM predicts a coarse 2D path (what/how to manipulate) from an image, and a small policy executes it using 3D observations
- Intermediate Representation: Uses '2D paths' (end-effector trajectory + gripper state) as the interface, which can be extracted from cheap sources like simulation or videos without needing robot actions
- Enables finetuning the high-level VLM on massive 'off-domain' datasets (simulation, pixel-tracking tasks, other robot embodiments) to bridge the sim-to-real gap
Architecture
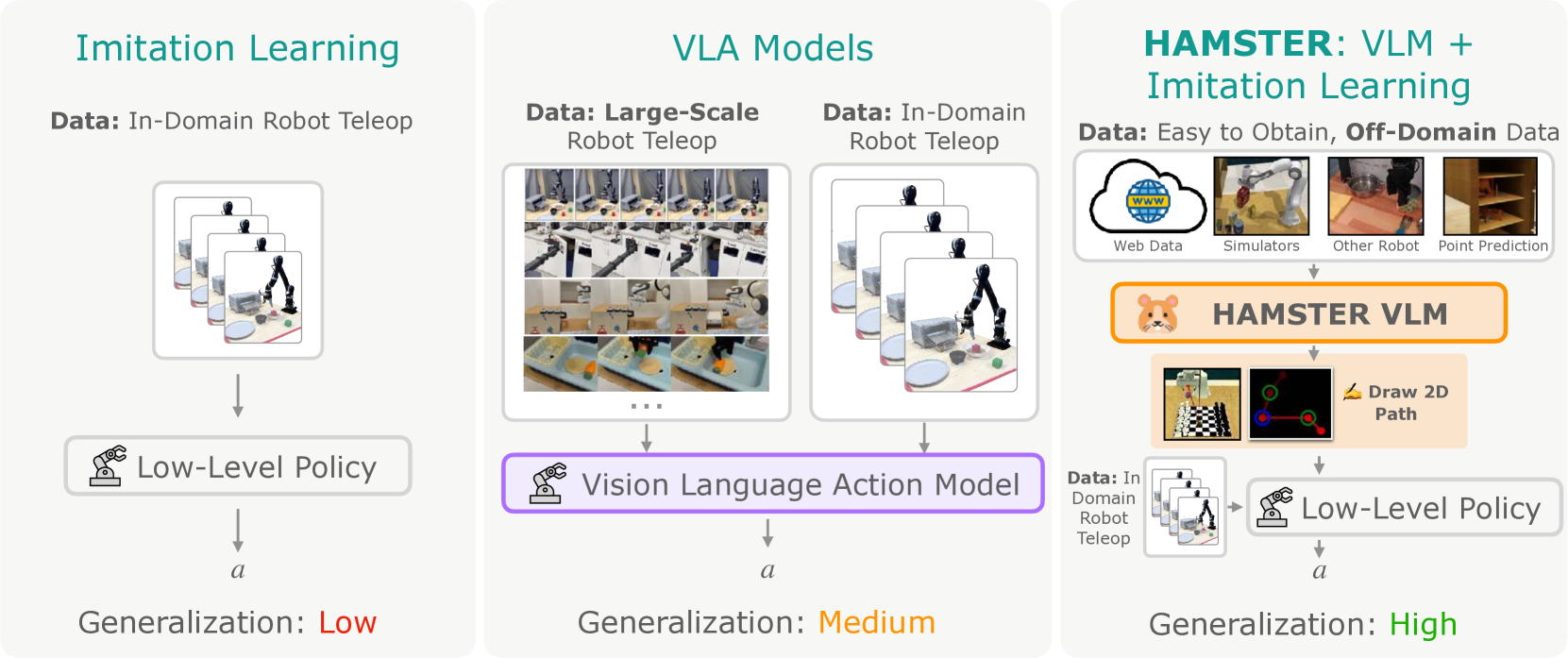
Conceptual diagram of the HAMSTER hierarchical architecture
Evaluation Highlights
- Achieves an average of 20% improvement in success rate across seven axes of generalization (embodiment, dynamics, visual appearance, etc.) compared to OpenVLA
- Represents a 50% relative gain in success rate over the OpenVLA baseline in real-robot experiments
- Demonstrates effective transfer from off-domain training data (simulation, diverse robot videos) to real-world deployment without seeing the test environment during VLM training
Breakthrough Assessment
8/10
Significantly addresses the data scarcity bottleneck in robotics by enabling VLAs to learn from abundant off-domain data (sim/video) via a hierarchical 2D path interface, showing strong real-world generalization.