📝 Paper Summary
Language-conditioned robotic manipulation
Zero-shot trajectory synthesis
Vision-Language Models (VLMs) for robotics
VoxPoser enables robots to perform open-ended manipulation tasks by using LLMs to write code that composes 3D cost maps, which then guide motion planners without requiring task-specific training data.
Core Problem
Existing methods for language-conditioned robot manipulation typically rely on pre-defined motion primitives or large-scale labeled robotic data, which bottlenecks generalization to new tasks and objects.
Why it matters:
- Pre-defined primitives limit the diversity of fine-grained actions a robot can perform.
- Collecting large-scale robotic data annotated with language instructions is expensive and laborious.
- Directly outputting high-frequency control signals from LLMs is impractical due to high dimensionality.
Concrete Example:
Given the instruction 'open the top drawer and watch out for the vase', standard methods might fail if they lack a specific 'avoid_vase' primitive. VoxPoser generates a 3D map where the drawer handle has high value (attraction) and the vase's vicinity has low value (repulsion), guiding the planner naturally.
Key Novelty
LLM-synthesized 3D Value Maps for Planning
- Uses LLMs (like GPT-4) to generate Python code that calls VLM APIs (like OWL-ViT) to locate objects.
- The generated code composes dense 3D voxel grids (value maps) representing affordances (where to go) and constraints (what to avoid) in observation space.
- These value maps serve as objective functions for a standard model-based motion planner (MPC), enabling zero-shot execution without training.
Architecture

The complete VoxPoser pipeline from instruction to motion planning.
Evaluation Highlights
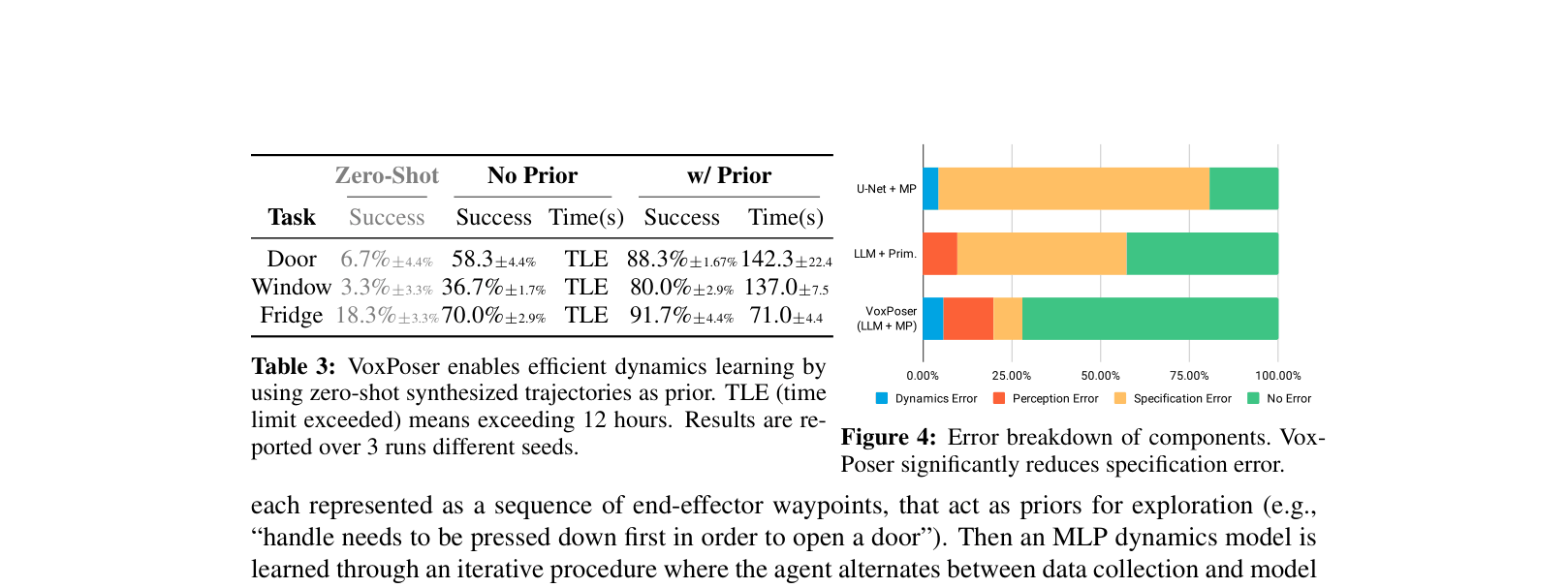
- Achieves 88.0% success rate on everyday real-world manipulation tasks, compared to 24.0% for Code as Policies (LLM + Primitives).
- Demonstrates 70% success rate under dynamic disturbances in the real world (0% for baselines).
- Outperforms learned cost-map baselines (U-Net) by large margins in simulation on unseen instructions (76.7% vs 0.0% for composition tasks).
Breakthrough Assessment
9/10
A significant leap in zero-shot robotic generalization. By bridging LLM reasoning with low-level planning via value maps, it removes the need for primitives or training data, solving a major bottleneck in embodied AI.