📝 Paper Summary
Vision-Language-Action (VLA) Models
Robotic Manipulation
HybridVLA integrates continuous diffusion and discrete autoregression into a single language model, using the latter's confidence to adaptively fuse actions for precise, robust robotic manipulation.
Core Problem
Existing methods force a trade-off: autoregressive models quantize actions (losing precision), while diffusion-based models typically use separate heads that fail to leverage the large language model's full token-level reasoning capabilities.
Why it matters:
- Discrete action bins in autoregressive models disrupt motion continuity, hindering tasks requiring fine motor control.
- Separated diffusion heads treat the language model merely as a feature extractor, missing out on the rich, step-by-step reasoning inherent in next-token prediction.
- Simply concatenating two policies is inefficient and ignores the potential for mutual reinforcement between semantic reasoning and continuous control.
Concrete Example:
In a task like 'Close laptop lid', an autoregressive model might produce jerky, quantized movements that fail to latch the lid smoothly. Conversely, a standard diffusion VLA might generate smooth motion but fail to reason about the sequence of steps if the instruction is complex, because the diffusion head is decoupled from the LLM's reasoning process.
Key Novelty
Unified Collaborative Generation
- Embeds diffusion denoising directly into the Large Language Model's (LLM) token stream using special markers (`<<<BOD>>>`), forcing the LLM to generate continuous action latents alongside discrete text/action tokens.
- Employs a collaborative ensemble mechanism where the model checks the confidence of its autoregressive (discrete) prediction; if high, it averages it with the diffusion (continuous) prediction for robustness.
Architecture
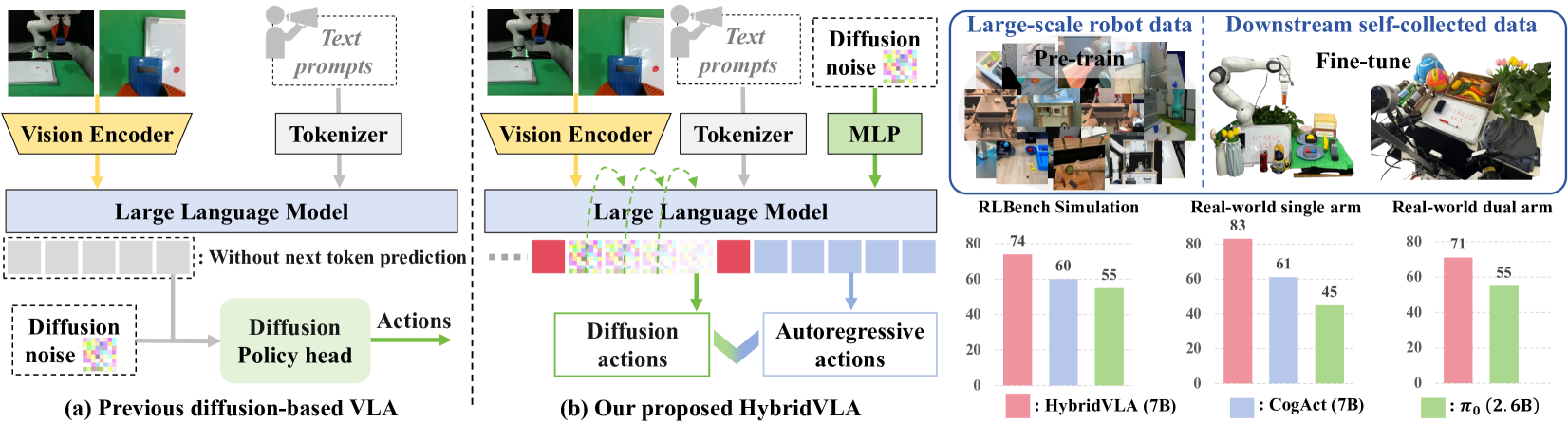
Comparison of HybridVLA against previous decoupled architectures, and the internal token sequence design.
Evaluation Highlights
- Outperforms previous state-of-the-art Vision-Language-Action (VLA) methods by 14% in mean success rate on simulation tasks.
- Achieves a 19% improvement in mean success rate on real-world manipulation tasks compared to baselines.
- Demonstrates generalization to unseen objects, backgrounds, and lighting, with a specialized inference variant running at 9.4 Hz.
Breakthrough Assessment
8/10
Successfully unifies two dominant but previously distinct paradigms (diffusion and autoregression) within a single backbone, yielding significant empirical gains in both sim and real-world robotics.