📝 Paper Summary
Vision-Language Models (VLM)
Mixture-of-Experts (MoE)
Efficient Multimodal Learning
Kimi-VL combines a native-resolution vision encoder with an efficient MoE language model and reinforcement learning to achieve strong multimodal reasoning and long-context understanding with only 2.8B activated parameters.
Core Problem
Existing open-source VLMs often rely on dense architectures that are computationally heavy, lack support for long Chain-of-Thought (CoT) reasoning, or use fixed-size vision encoders that struggle with varying resolutions.
Why it matters:
- Traditional fixed-size vision encoders require complex splitting/splicing for high-resolution inputs, limiting adaptability
- Most efficient open-source VLMs lack the long-horizon reasoning capabilities (System 2 thinking) seen in proprietary models like o1 or Kimi k1.5
- Dense architectures scale poorly compared to Mixture-of-Experts (MoE) for high-throughput deployment
Concrete Example:
When processing high-resolution images or long documents, models with fixed positional embeddings (like SigLIP's original implementation) fail to generalize because interpolated embeddings become inadequate as resolution increases, causing fine-grained details to be lost.
Key Novelty
Kimi-VL (Efficient MoE VLM with Long-Thinking)
- Integrates a native-resolution vision encoder (MoonViT) that uses sequence packing (NaViT-style) and 2D Rotary Positional Embeddings to handle variable aspect ratios without padding
- Employs a multi-stage training pipeline culminating in Reinforcement Learning (RL) to internalize long Chain-of-Thought reasoning strategies (planning, reflection) for multimodal tasks
Architecture
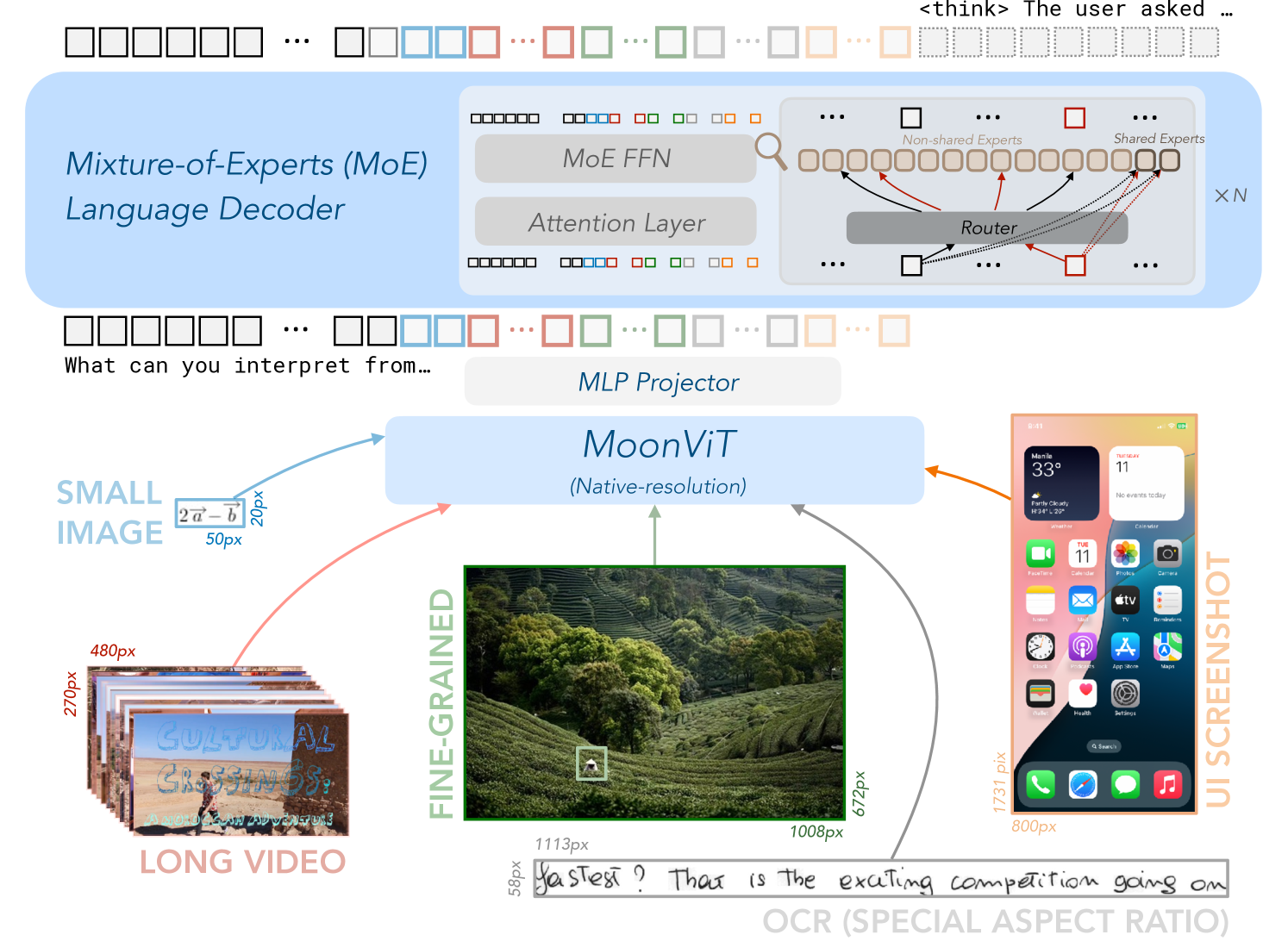
The architectural components and data flow of Kimi-VL.
Evaluation Highlights
- Achieves 64.0 on MMMU (multimodal reasoning) with Kimi-VL-Thinking, demonstrating strong reasoning capabilities
- Scores 80.1 on MathVista and 83.2 on V* (high-resolution perception), showing robust fine-grained visual understanding
- Attains 64.5 on LongVideoBench using a 128K context window, effectively handling long-context video understanding
Breakthrough Assessment
8/10
Delivers competitive reasoning and long-context performance in a highly efficient 2.8B activated parameter package, bridging the gap between open-source efficient models and flagship proprietary systems.
