📊 Experiments & Results
Evaluation Setup
Multimodal image generation and editing evaluation using human preference (ELO) and automated benchmarks
Benchmarks:
- Artificial Analysis Arena (Human preference ELO leaderboard)
- MagicBench 4.0 (Multimodal benchmark (T2I, Single-Edit, Multi-Edit)) [New]
- DreamEval (Automated visual-question-answer scoring) [New]
Metrics:
- ELO Score
- Inference Time (seconds)
- GSB (Composite metric for alignment, consistency, structure)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Internal Benchmarking | Inference Acceleration (FLOPs) | 1.0 | 10.0 | +9.0 |
| Internal Benchmarking | Inference Time (2K Image) | Not reported in the paper | 1.4 | Not reported in the paper |
Experiment Figures
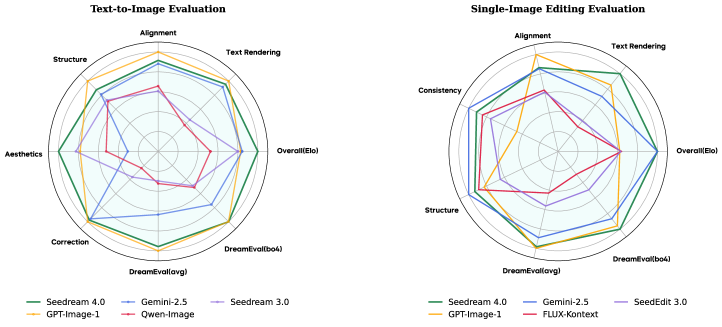
Radar charts comparing Seedream 4.0, GPT-Image-1, and Gemini 2.5 on T2I and Editing dimensions
Main Takeaways
- Seedream 4.0 ranks #1 in Artificial Analysis Arena for both Text-to-Image and Editing, surpassing GPT-Image-1 and Flux.
- In multi-image editing, Seedream 4.0 outperforms GPT-Image-1 and Gemini 2.5 by almost 20% on the GSB metric, showing superior structural integrity with multiple reference images.
- The model demonstrates a strong trade-off balance: unlike GPT-Image-1 (high adherence, low consistency) or Gemini 2.5 (high preservation, low adherence), Seedream 4.0 maintains high scores in both.