📝 Paper Summary
Robot Foundation Models
Vision-Language-Action (VLA) Models
Dexterous Manipulation
π₀ is a generalist robot foundation model that fine-tunes a vision-language model to generate continuous, high-frequency physical actions via flow matching, enabling dexterous control across diverse robot embodiments.
Core Problem
Current robot learning methods struggle with dexterity and generalization because standard VLM (Vision-Language Model) tokenization cannot adequately represent complex, high-frequency continuous actions, and data is scarce.
Why it matters:
- Specialized robot policies lack versatility and cannot recover from unexpected perturbations or handle diverse objects.
- Prior VLA models using discrete autoregressive tokens struggle with high-frequency control (e.g., 50 Hz) needed for dynamic tasks.
- Developing generalist robots requires a recipe to combine internet-scale semantic knowledge with physical dexterity.
Concrete Example:
A standard VLM-based robot policy might successfully identify a shirt but fail to fold it because the intricate, high-speed motions required for folding cannot be represented well by low-frequency discrete tokens.
Key Novelty
Flow-Matching Vision-Language-Action (VLA) Model
- Integrates a continuous flow matching (diffusion-style) head directly into a pre-trained VLM backbone, allowing the model to output precise, multimodal continuous action distributions.
- Uses an 'action expert' architecture: a separate set of weights for processing robotics-specific tokens (actions/state) while sharing the VLM backbone for images and text.
- Adopts an LLM-style training recipe: massive cross-embodiment pre-training for general physical understanding followed by targeted post-training for high-quality task execution.
Architecture
The π₀ model architecture and training pipeline.
Evaluation Highlights
- Controls robots at frequencies up to 50 Hz, enabling highly dynamic tasks like laundry folding and box assembly.
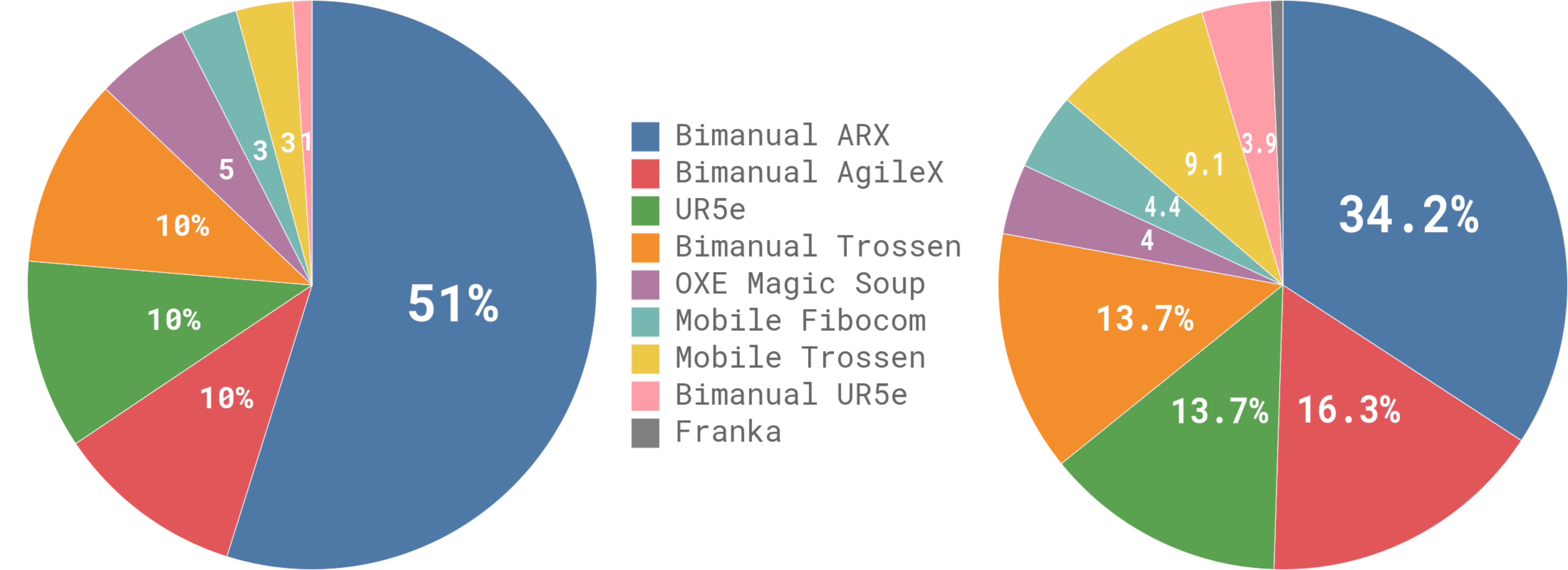
- Trained on a massive dataset of 10,000 hours (903M timesteps) of dexterous manipulation data across 7 diverse robot configurations.
- Demonstrates capability on long-horizon tasks (tens of minutes) involving combinatorial complexity, such as clearing a table with novel objects.
Breakthrough Assessment
8/10
Significant architectural advance by successfully combining VLMs with flow matching for high-frequency control, scaled to an unprecedented 10,000 hours of dexterous robot data.