📝 Paper Summary
Document Parsing
Vision-Language Models (VLMs)
Optical Character Recognition (OCR)
PaddleOCR-VL-1.5 combines a geometry-aware layout engine with a compact 0.9B vision-language model to achieve robust parsing of physically distorted documents and support text spotting.
Core Problem
Existing document parsers are optimized for flat, digital-born documents and fail when facing real-world physical distortions like warping, skewing, and erratic lighting.
Why it matters:
- Real-world documents captured via mobile phones often exhibit non-rigid warping and severe perspective skew, breaking standard axis-aligned detection models.
- Accurate parsing is the prerequisite for RAG (Retrieval-Augmented Generation) systems to ingest knowledge, but current failures in layout analysis lead to jumbled or missing context.
- Most state-of-the-art models are too computationally heavy or lack specific training for 'in-the-wild' noise like screen moiré patterns or seals.
Concrete Example:
When parsing a receipt photographed at a steep angle with a curved surface, standard models predict overlapping rectangular boxes that mix text columns. PaddleOCR-VL-1.5 uses pixel-accurate segmentation to isolate the curved text regions and correctly orders them.
Key Novelty
Geometry-Aware Robust Document Parsing (PaddleOCR-VL-1.5)
- Replaces standard bounding box detection with PP-DocLayoutV3, a mask-based instance segmentation engine that handles non-planar/warped document shapes.
- Integrates reading order prediction directly into the layout transformer's decoder, allowing simultaneous geometric localization and logical sequencing in one pass.
- Expands the VLM's capabilities to include Seal Recognition and Text Spotting (grounded OCR) within a compact 0.9B parameter budget.
Architecture
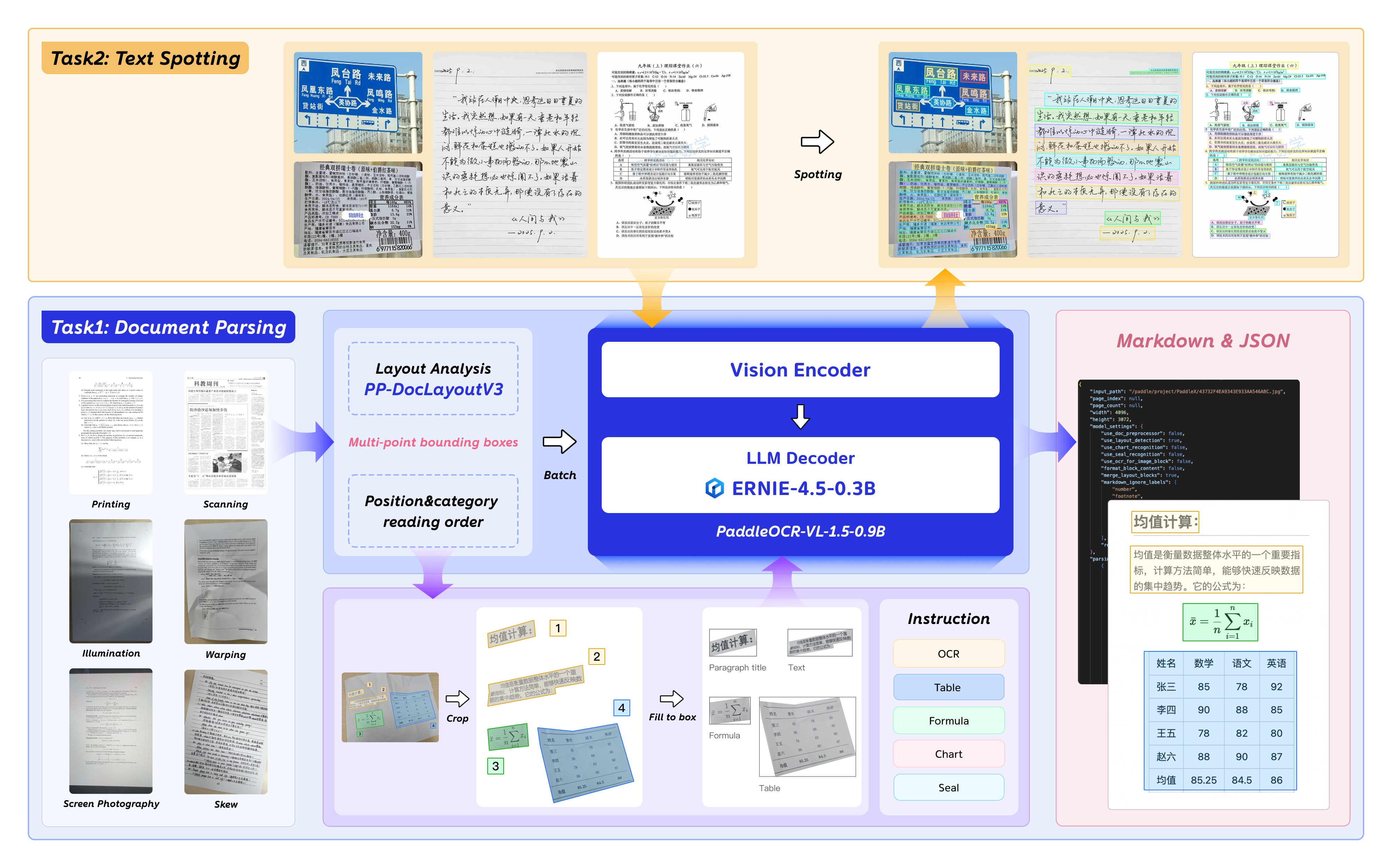
The dual-path framework for Document Parsing and Text Spotting.
Evaluation Highlights
- Achieves 94.5% accuracy on OmniDocBench v1.5, establishing a new state-of-the-art for general document parsing.
- Achieves 92.05% overall accuracy on the newly curated Real5-OmniDocBench, which specifically targets physical distortions like warping and skew.
- Outperforms massive general VLMs (Vision-Language Models) like Qwen3-VL-235B and Gemini-3 Pro on robustness benchmarks despite having only 0.9B parameters.
Breakthrough Assessment
8/10
Significant engineering advance in robust document parsing. The shift to mask-based layout analysis for distorted docs addresses a major pain point, and the 0.9B efficiency is highly practical.