📝 Paper Summary
Factual Knowledge Assessment
Hallucination detection
The authors propose assessing an LM's factual knowledge by checking if it assigns higher probability to the correct entity than to a set of carefully selected incorrect 'distractor' entities.
Core Problem
Existing methods for assessing factual knowledge (like cloze sentences) suffer from 'out-of-subject' continuations where the model generates grammatically correct but irrelevant text, or struggle with multiple correct verbalizations.
Why it matters:
- Verifying that a model generates 'Poland' after 'Germany shares a border with' is insufficient if the model merely guessed or if valid alternatives exist
- Current metrics like Precision@k fail for multi-token answers, while probability-based metrics are hard to interpret or compare across models
- Verbalization artifacts (e.g., missing determiners in templates) often break existing assessment metrics, leading to false negatives in knowledge assessment
Concrete Example:
For the fact (France, capital, Paris), a cloze sentence 'The capital of France is...' might be continued with 'a city of contrasts' (Out-Of-Subject) instead of 'Paris'. While linguistically valid, this continuation fails to reveal if the model actually knows the capital is Paris.
Key Novelty
Distractor-Based Knowledge Assessment (Min@n / Avg@n)
- Instead of generating text, the method compares the probability of the correct object against a set of 'distractors' (incorrect but plausible alternatives of the same type)
- A fact is considered 'known' only if the model assigns higher plausibility to the correct object than to the distractors (specifically using a Minimum aggregation function for strictness)
- Introduces multiple strategies for retrieving distractors, finding that 'Approximate Optimal' (ApprOpt) distractors—those the model itself considers highly probable—are the hardest and most effective
Architecture
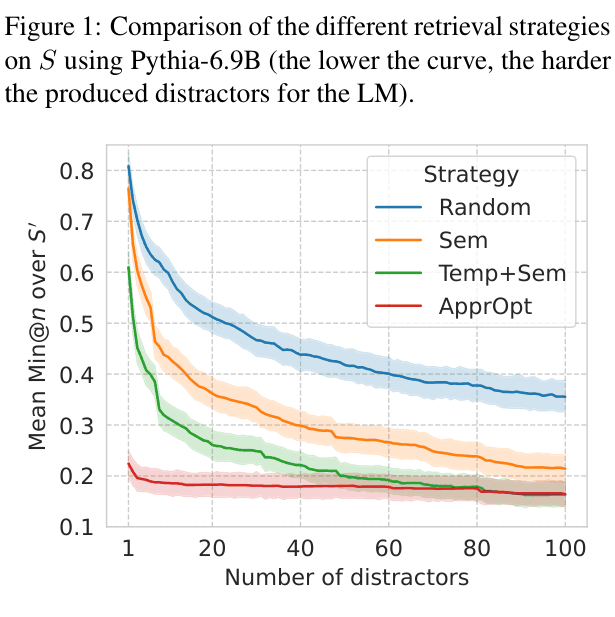
Comparison of distractor strategies (Random, Temp+Sem, ApprOpt) by measuring how 'hard' they are for the model (lower Min@n score = harder).
Evaluation Highlights
- The proposed measure (using ApprOpt distractors) achieves a Kendall's τ correlation of 0.282 with human judgment, outperforming BERT-score (0.159) and Precision@n (0.185)
- The method is highly robust to verbalization artifacts (e.g., template errors), achieving a consistency score (Kendall's τ) of 0.92 between correct and flawed prompts, compared to 0.47 for ROUGE-L
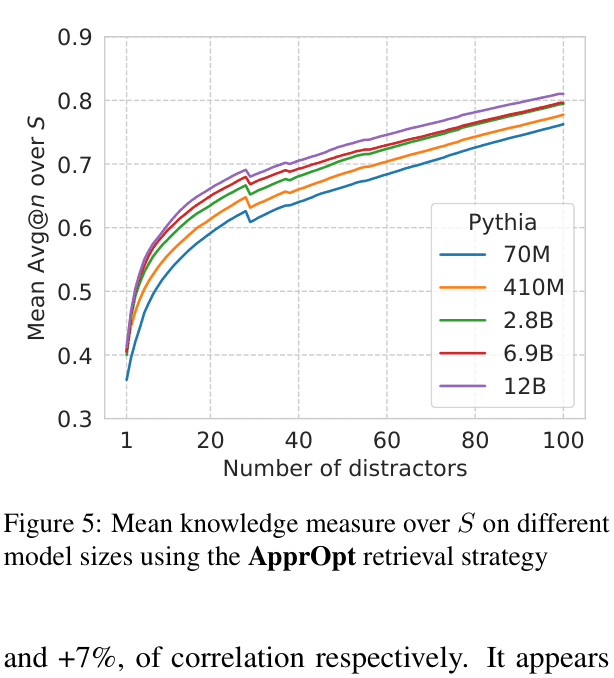
- Larger models are slightly more robust to distractors, but even a 12B model only reaches ~0.80 Avg@20 score, suggesting LMs remain vulnerable to plausible incorrect alternatives
Breakthrough Assessment
7/10
Offers a robust, interpretable alternative to generation-based evaluation. While not a fundamental architecture change, it significantly improves the reliability of knowledge assessment methodologies.