📊 Experiments & Results
Evaluation Setup
Instruction fine-tuning evaluation and Benchmark correlation analysis
Benchmarks:
- MMMU (Multi-discipline multimodal reasoning)
- HallusionBench (Visual hallucination diagnosis)
- WV-Bench (WildVision-Bench) (Human preference approximation)
- VisionArena-Bench (Human preference approximation) [New]
Metrics:
- Accuracy
- Spearman Correlation
- Kendall Tau Correlation
- Statistical methodology: Bootstrap resampling (100 times) to construct confidence intervals for Bradley-Terry ratings
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Fine-tuning experiments demonstrate that training on real-world VisionArena data significantly outperforms training on synthetic datasets (Llava-Instruct) across multiple benchmarks. | ||||
| MMMU | Accuracy | 38.7 | 45.2 | +6.5 |
| WV-Bench | Score | 10.4 | 56.9 | +46.5 |
| HallusionBench | Figure QA Accuracy | 1067.6 | 1437.0 | +369.4 |
| Benchmark analysis shows VisionArena-Bench correlates much better with live human voting data than previous baselines. | ||||
| Chatbot Arena Leaderboard | Spearman Correlation | 80.2 | 97.3 | +17.1 |
| Chatbot Arena Leaderboard | Kendall Tau Correlation | 69.2 | 89.7 | +20.5 |
Experiment Figures
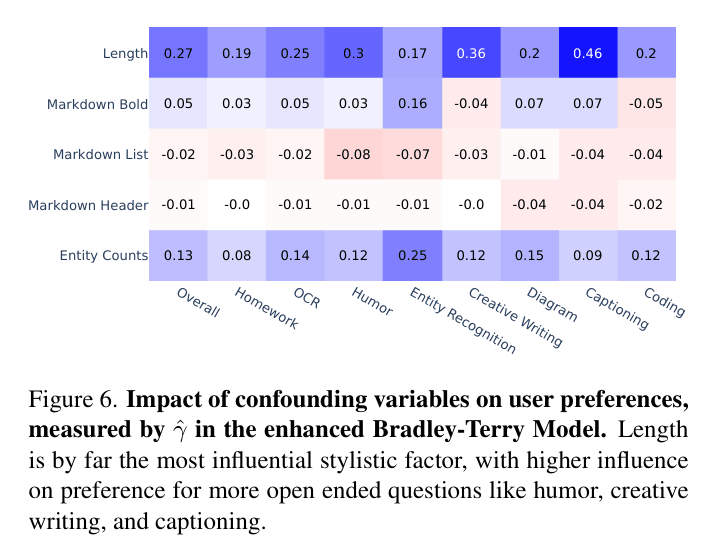
Impact of confounding variables (style) on user preferences across different task categories
Main Takeaways
- Response style (e.g., length, markdown formatting) heavily influences human preference, especially in open-ended tasks like captioning and humor
- Current VLMs struggle significantly with 'visual puns' and complex spatial reasoning (e.g., finding the 'square root' of a cat), often failing where humans succeed easily
- Fine-tuning on diverse, real-world user interactions (VisionArena) yields far better generalization and alignment than training on static/synthetic datasets (Llava-Instruct)