📝 Paper Summary
Vision-Language Pre-training
Multimodal Retrieval
Fine-grained Image-Text Alignment
FLAIR improves fine-grained visual understanding in vision-language models by using text-conditioned attention pooling and diverse sub-caption sampling to create localized image representations aligned with detailed textual descriptions.
Core Problem
Standard CLIP models align images and texts globally, losing track of local image details and failing to distinguish specific regions or objects described in fine-grained prompts.
Why it matters:
- Global alignment (like in CLIP) compresses an entire image into one vector, losing spatial nuance needed for tasks like segmentation or object localization
- Existing methods that use long captions often rely on indirect alignment through global contrastive loss, which doesn't force the model to learn local correspondences
- Without targeted negative pairs, models can shortcut the learning process by matching text-to-text rather than aligning visual features with language
Concrete Example:
CLIP cannot perceive the difference between 'background' and 'frappucino' in an image, failing to highlight relevant regions. Similarly, standard models trained on long captions might not distinguish between a caption describing a specific local object vs. the whole scene if negative pairs aren't carefully selected.
Key Novelty
Text-Conditioned Attention Pooling with Diverse Caption Sampling
- Instead of a single global image embedding, FLAIR generates image representations conditioned on the specific text query using an attention pooling mechanism
- Uses a diverse sampling strategy on long synthetic captions to create batches containing both global summaries and local object descriptions, forcing the model to learn both coarse and fine-grained alignment
- Introduces a specific negative pair selection strategy where the image embedding conditioned on text A is contrasted against text B, preventing the model from ignoring visual data
Architecture
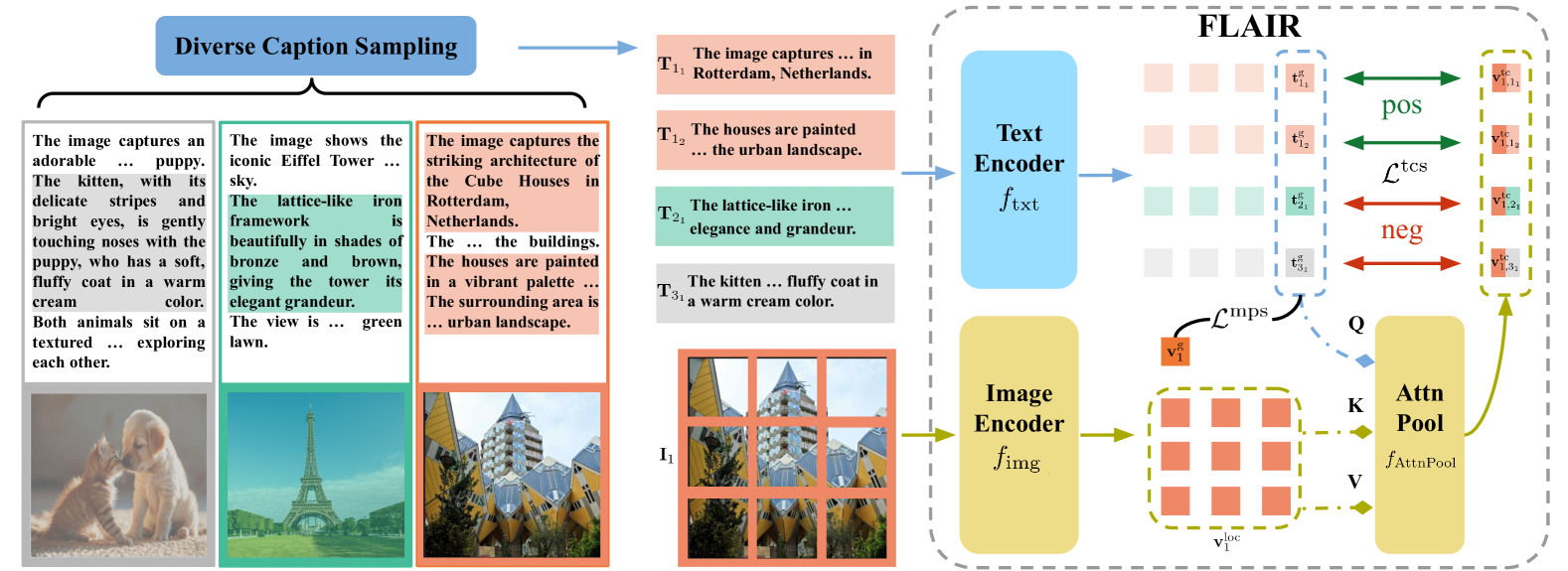
Overview of FLAIR architecture including caption sampling, text-conditioned attention pooling, and loss computation.
Evaluation Highlights
- Outperforms CLIP models trained on billions of data samples by an average of 14.4% mIoU on zero-shot semantic segmentation tasks, despite using only 30M samples
- +10.8% R@1 improvement on coarse-to-fine multimodal retrieval compared to previous models trained on similar data scales
- Achieves 90.8% R@1 on DOCCI-FG (fine-grained retrieval), significantly surpassing the DreamLIP baseline (84.1%) on the same CC12M-recap dataset
Breakthrough Assessment
8/10
Significant efficiency gains (beating billion-scale models with 30M samples) and a clever architectural change (text-conditioned pooling) that directly addresses the granularity bottleneck in CLIP.
