📝 Paper Summary
Remote Sensing
Vision-Language Model Evaluation
Earth Observation
GEOBench-VLM is a comprehensive benchmark comprising 10,000 manually verified instructions to evaluate how well Vision-Language Models handle specific challenges in satellite and aerial imagery.
Core Problem
Generic Vision-Language Models (VLMs) and existing benchmarks fail to address specific geospatial challenges like tiny object detection, diverse object scales, non-optical data, and temporal change detection.
Why it matters:
- Critical applications like disaster management, urban planning, and environmental monitoring rely on accurate automated analysis of complex satellite imagery.
- Existing benchmarks (e.g., MMMU, SEED-Bench) focus on general scenes, while geospatial-specific ones often lack temporal analysis, segmentation, or non-optical data support.
- Current models frequently hallucinate or fail on tasks involving counting dense objects or interpreting multi-temporal satellite data.
Concrete Example:
In object counting tasks, models like GPT-4o often fail when answer options deviate slightly from the truth (e.g., ±20%), showing weak numerical reasoning. Additionally, generic models struggle to classify crops in low-resolution satellite images where temporal patterns are key.
Key Novelty
GEOBench-VLM Benchmark Suite
- Integrates 8 broad categories and 31 fine-grained tasks specifically for geospatial analysis, including unique requirements like non-optical imagery (SAR) and multi-temporal change detection.
- Utilizes a rigorous data pipeline combining open datasets with GPT-4o assisted question generation, followed by manual verification to ensure high-quality Multiple-Choice Questions (MCQs).
- Evaluates both generic state-of-the-art VLMs and specialized geospatial models to identify distinct performance gaps in domain-specific tasks.
Architecture
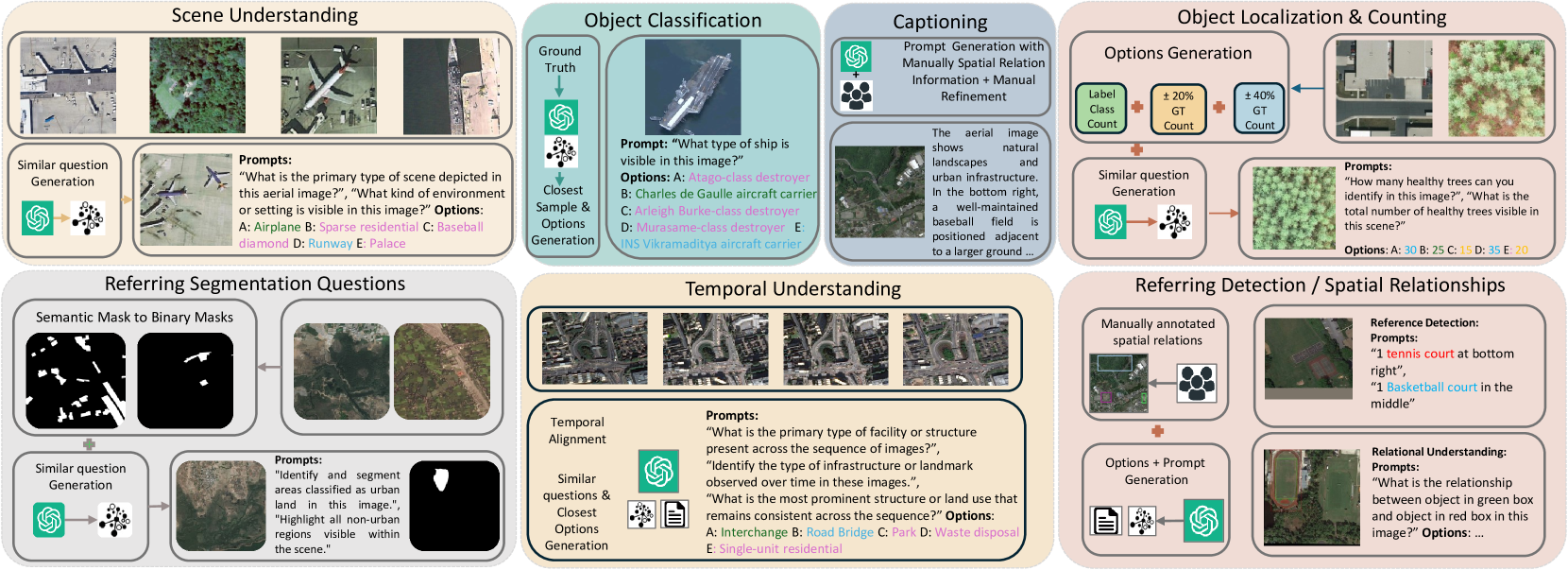
The data curation pipeline for GEOBench-VLM.
Evaluation Highlights
- The best-performing model, LLaVa-OneVision, achieves only 41.7% accuracy on MCQs, which is approximately double the random guess performance but indicates significant room for improvement.
- GPT-4o excels in object classification and land use tasks but performs worst in referring expression detection with precision scores significantly lower than open-source models like Sphinx.
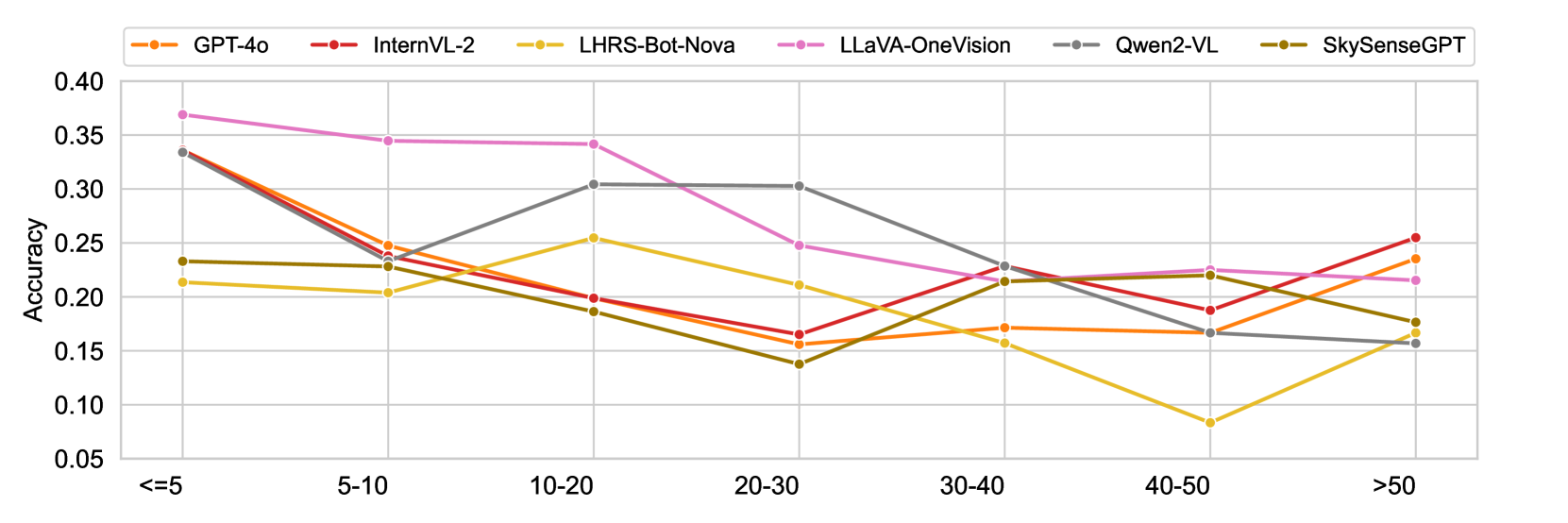
- In counting tasks, model accuracy drops significantly as object density increases (>50 objects), with InternVL2 and GPT-4o showing better resilience in high-density scenarios.
Breakthrough Assessment
7/10
Strong contribution to the specific domain of geospatial VLM evaluation with a comprehensive, manually verified dataset. It highlights significant gaps in current SOTA models, though it is a benchmark rather than a new modeling technique.