📝 Paper Summary
GUI Agents
Vision-Language Models (VLMs)
R-VLM improves GUI element localization by using a two-stage zoom-in mechanism and an IoU-weighted loss function that teaches the model to prioritize coordinate precision.
Core Problem
Existing vision-only GUI agents struggle to precisely localize elements because they process cluttered high-resolution screenshots directly and use token-based losses that ignore spatial overlap quality.
Why it matters:
- Inaccurate grounding leads to failed clicks and broken automation workflows in real-world applications.
- Current cross-entropy losses treat numeric coordinates as independent tokens, failing to penalize near-misses differently from far-off errors.
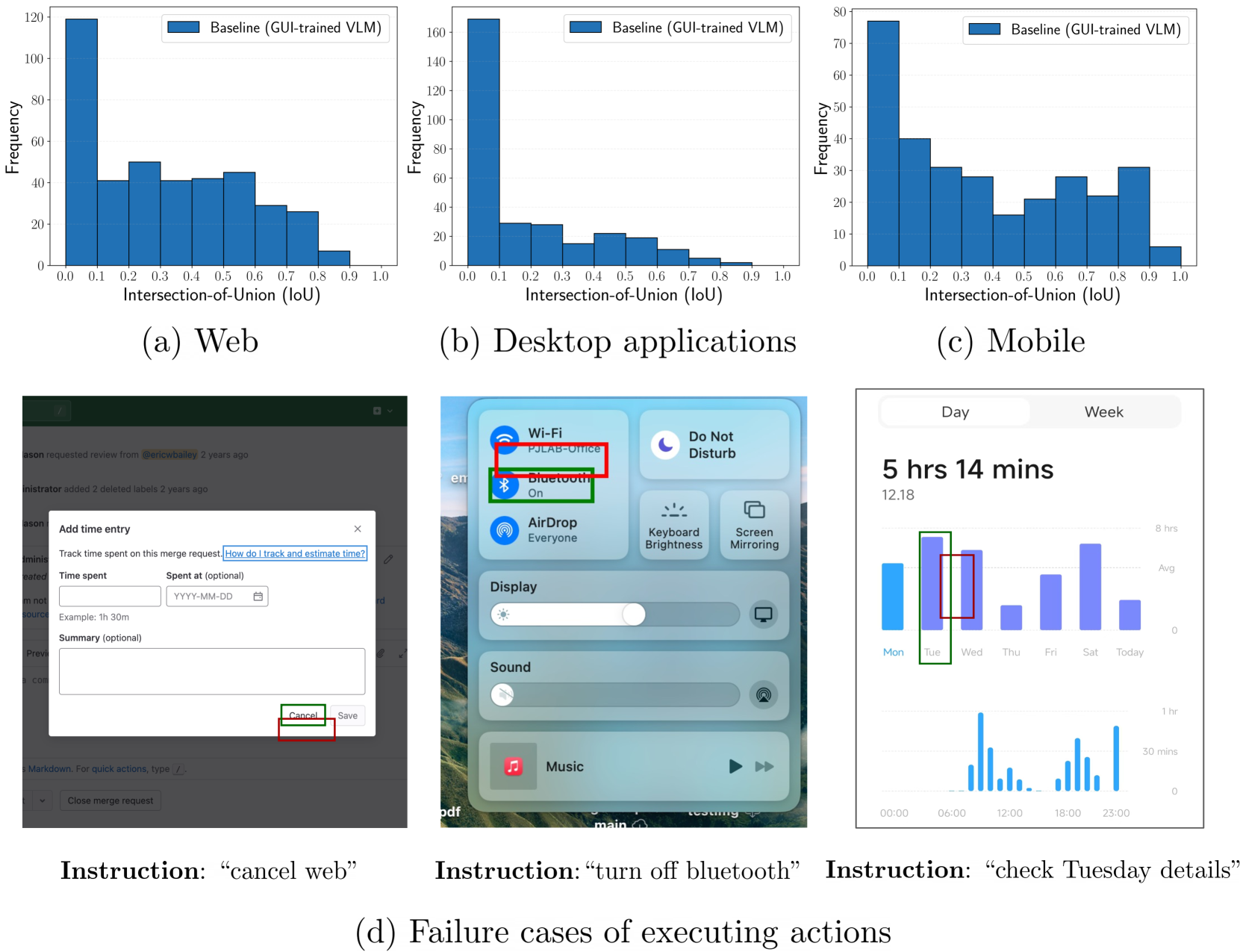
- Small icons and complex layouts are difficult to resolve without focused processing, a known challenge in object detection.
Concrete Example:
A user asks to 'Delete this mail', but the model predicts a bounding box centered slightly off the trash can icon (low IoU). Because the prediction is technically a different token sequence, standard training penalizes it equally to a completely wrong prediction, failing to guide the model toward the precise center.
Key Novelty
Two-Stage Zoom-In with IoU-Aware Optimization
- Adopts a 'Region Proposal' strategy: the model makes a coarse initial prediction, then crops and zooms into that region to make a refined, high-resolution prediction.
- Replaces standard cross-entropy with an IoU-weighted objective where training samples include 'pseudo' boxes (noisy variations) weighted by their overlap with the ground truth, teaching the model that spatial proximity matters.
Architecture
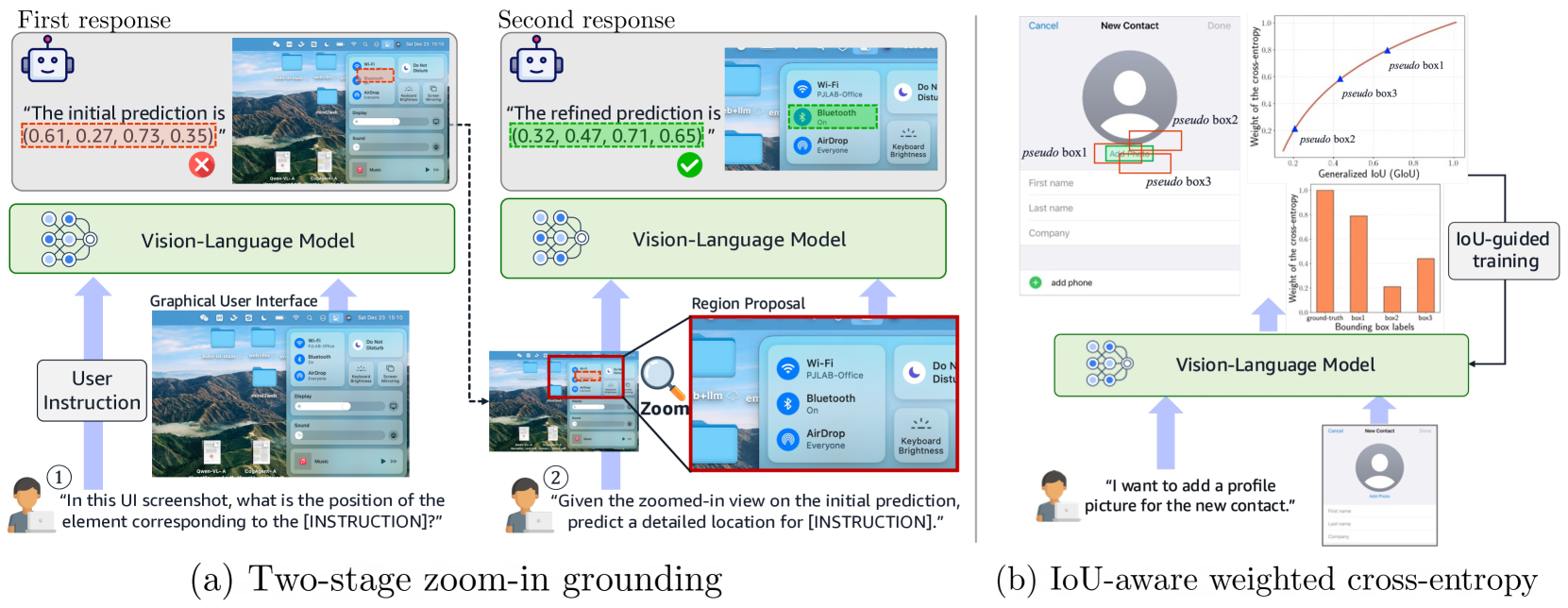
Comparison between standard VLM grounding and the proposed R-VLM framework.
Evaluation Highlights
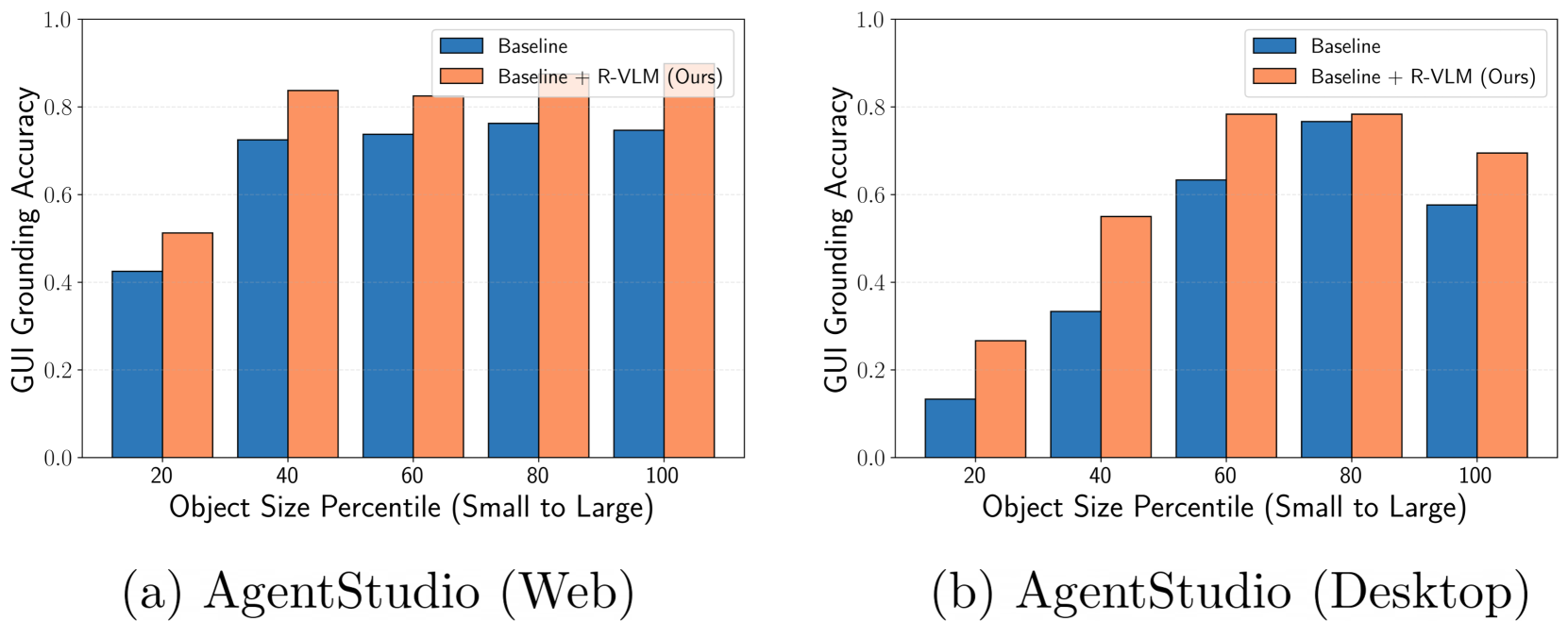
- +13% absolute improvement in GUI grounding accuracy across mobile, desktop, and web platforms (ScreenSpot and AgentStudio benchmarks) compared to state-of-the-art SeeClick.
- +3.2% to +9.7% absolute accuracy improvements on downstream GUI navigation tasks (AITW and Mind2Web benchmarks).
- Demonstrates that the two-stage zoom-in method improves performance even when applied to VLMs in a training-free manner.
Breakthrough Assessment
7/10
Successfully adapts proven object detection concepts (Region Proposals, IoU regression) to VLM-based agents, yielding significant accuracy gains. The contribution is methodological refinement rather than a new paradigm.