📝 Paper Summary
3D Visual Grounding
VLM Agents
Zero-Shot Scene Understanding
VLM-Grounder is a zero-shot agent that locates 3D objects by dynamically stitching 2D image sequences for a VLM to reason about, then refining the location via multi-view ensemble projection.
Core Problem
Existing zero-shot 3D grounding methods rely on object-centric point cloud modules that miss scene context, while direct VLM usage struggles with context limits when processing long image sequences.
Why it matters:
- Robots need to understand complex natural language queries about 3D environments (e.g., 'find the room with the most light') which current point-cloud-based methods fail to grasp due to lack of visual context
- Supervised methods require scarce and expensive 3D-language paired data, limiting open-world application
- Standard VLM usage is bottlenecked by maximum image limits and context window consumption, making it hard to process full 3D scans
Concrete Example:
For a query like 'find the room with the most abundant natural light', previous methods using only object-centric point clouds fail because they lack visual scene context (lighting). VLM-Grounder processes actual images to perceive lighting conditions and locate the target.
Key Novelty
Dynamic Stitching and Multi-View Ensemble for VLM Agents
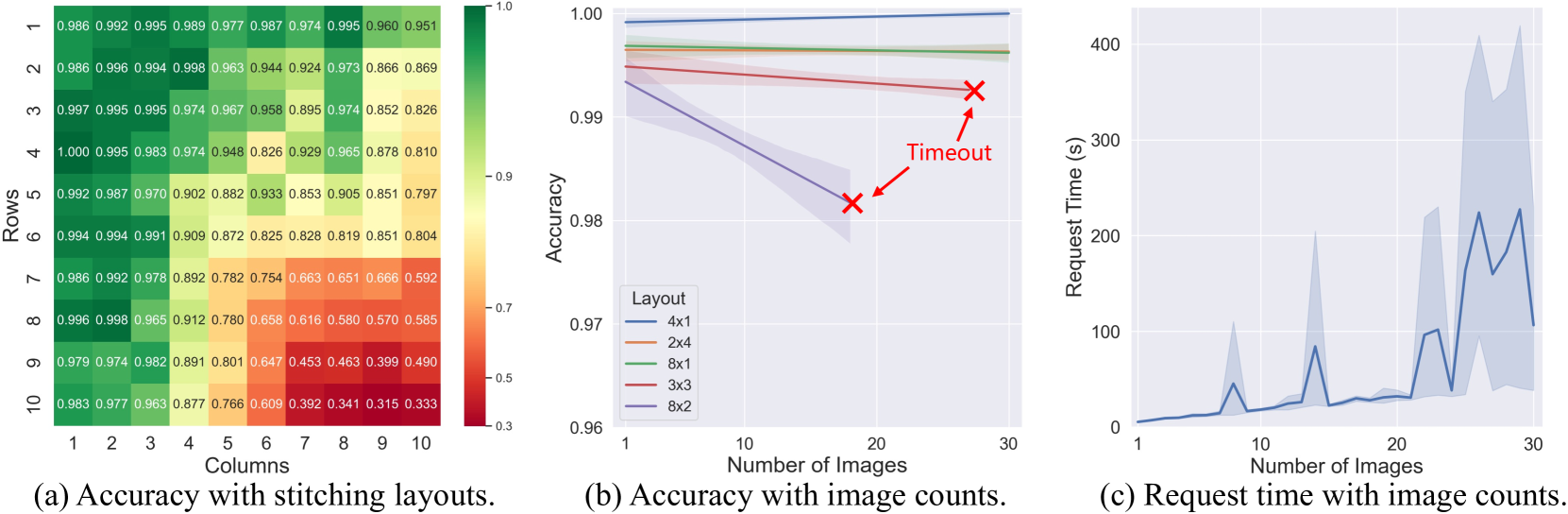
- Dynamic Stitching Strategy: Instead of feeding raw image sequences, images are stitched into grids (e.g., 4x1, 2x4) based on optimal layouts found via a new retrieval benchmark, maximizing VLM information intake within token limits.
- Multi-View Ensemble Projection: Refines 3D localization by finding the target object in multiple views using image matching, projecting 2D masks from all views into 3D space, and filtering noise.
Architecture
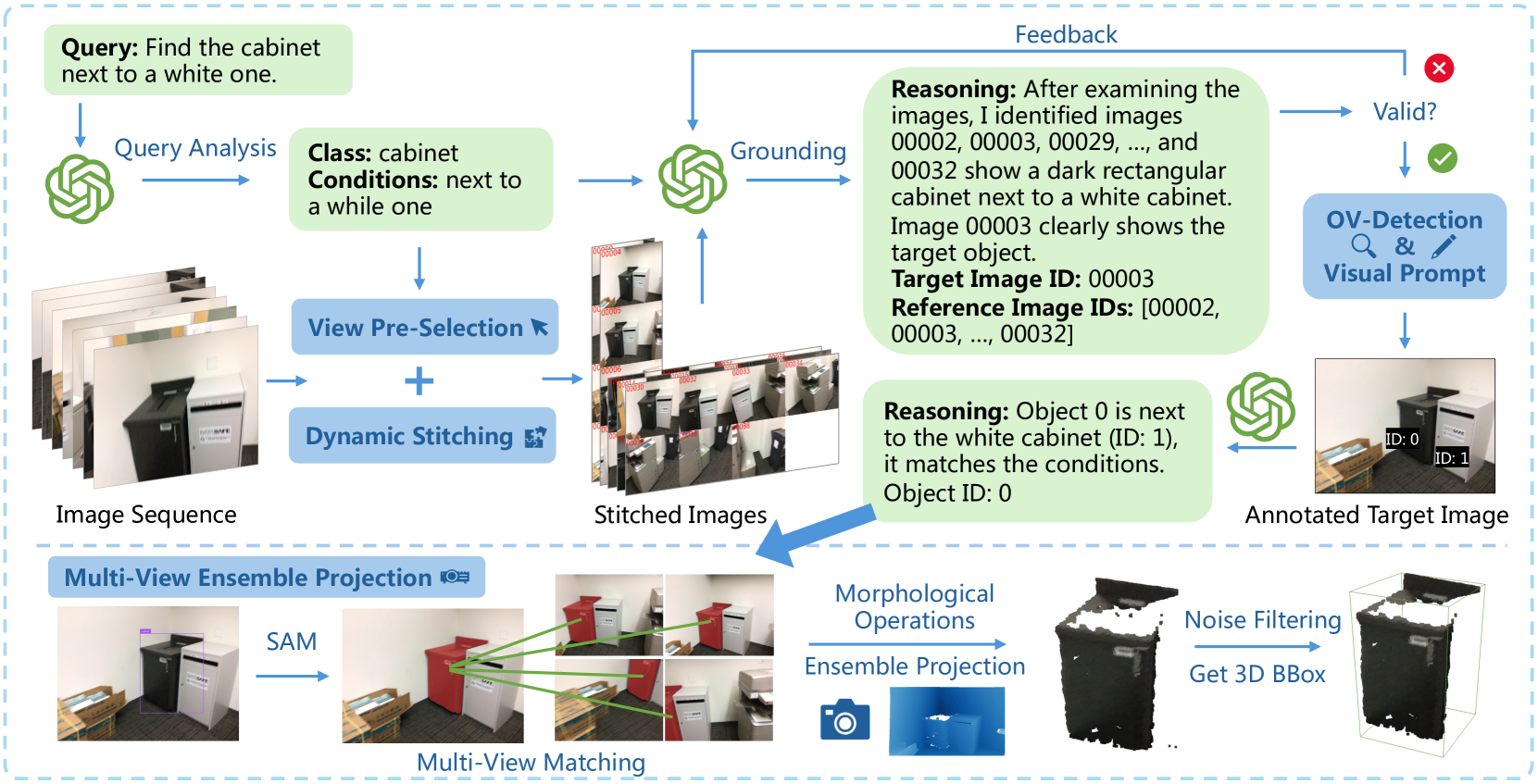
The complete inference pipeline of VLM-Grounder from user query to 3D bounding box.
Evaluation Highlights
- Achieves 51.6% Acc@0.25 on the ScanRefer benchmark, outperforming the previous zero-shot SOTA (ZS3DVG) by +15.2 points.
- Achieves 48.0% overall accuracy on the Nr3D benchmark, surpassing ZS3DVG (39.0%) without using any ground truth 3D bounding boxes or point clouds.
- Outperforms supervised baseline InstanceRefer (40.2% Acc@0.25) on ScanRefer without any training.
Breakthrough Assessment
8/10
Significant performance leap (+15%) over previous zero-shot methods while removing the dependency on pre-processed point clouds or 3D object priors. Demonstrates that 2D-only VLMs can effectively solve 3D tasks via agentic workflows.