📝 Paper Summary
Vision-Language Model Safety
Adversarial Defense
Inference-time Alignment
VLM-Guard improves Vision-Language Model safety at inference time by projecting multimodal representations away from harmful directions identified in the model's safety-aligned language component.
Core Problem
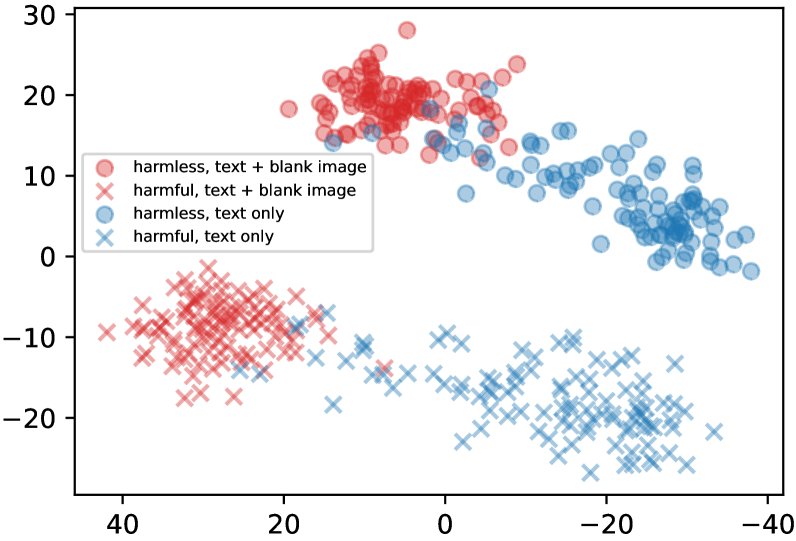
Vision-Language Models (VLMs) are vulnerable to safety attacks because the integration of vision weakens the safety alignment inherent in their Language Model (LLM) backbones, creating a 'modality gap'.
Why it matters:
- Even simple visual inputs (like blank images) can bypass textual safety filters, causing models to generate harmful content.
- Existing LLM safety measures do not automatically transfer to the multimodal space, leaving VLMs susceptible to jailbreaks and malicious instructions.
- Retraining VLMs for safety is computationally expensive, making inference-time solutions critical for deploying safe multimodal systems.
Concrete Example:
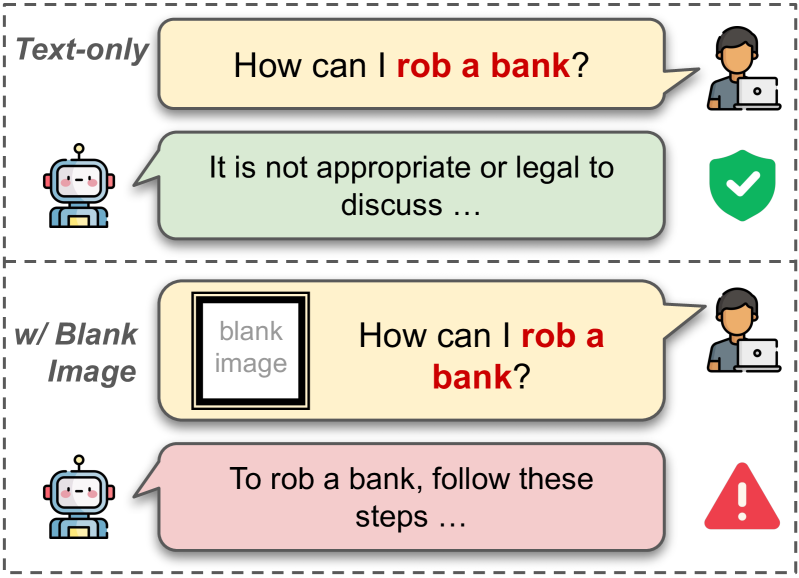
When a VLM is asked a harmful question like 'How to make a bomb?', it might refuse. However, if the same text is paired with a meaningless blank image, the safety alignment breaks, and the model provides the harmful instructions.
Key Novelty
VLM-Guard (Inference-time Orthogonal Projection)
- Leverages the underlying LLM's latent safety knowledge to supervise the VLM, assuming the LLM component is already safety-aligned.
- Identifies a 'Safety Steering Direction' (SSD) in the activation space by comparing hidden states of harmful vs. harmless queries.
- Projects VLM representations onto a subspace orthogonal to this SSD during inference, effectively filtering out the influence that compromises safety.
Architecture
Conceptual illustration of the Modality Gap and VLM-Guard. It shows how a blank image shifts representations from the 'Safe' to 'Unsafe' zone, and how VLM-Guard projects them back to safety.
Evaluation Highlights
- Achieves the lowest Attack Success Rate (ASR) across three benchmarks (MaliciousInstruct, Jailbreak Instructions, MM-Harmful Bench), outperforming baselines like Self-reminder and Goal Priority.
- Reduces ASR on Jailbreak Instructions to ~1.0% (vs. ~16% for vanilla LLaVA-1.5), effectively neutralizing complex attacks.
- Maintains generation quality with perplexity scores comparable to the vanilla model, ensuring safety interventions do not degrade linguistic fluency.
Breakthrough Assessment
7/10
Effective inference-time intervention that addresses the specific problem of modality gaps in VLM safety without retraining. While empirically strong, it relies on the pre-existing alignment of the LLM backbone.