📝 Paper Summary
3D Hand Pose Estimation
Egocentric Action Recognition
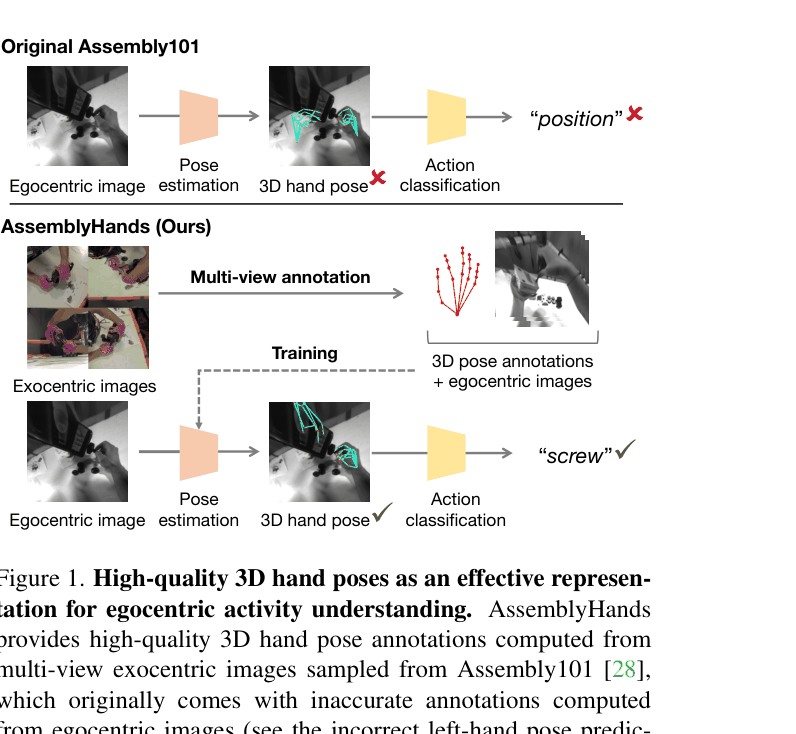
AssemblyHands creates a massive dataset of accurate 3D hand poses by projecting annotations from multi-view exocentric cameras onto egocentric views, demonstrating that better pose quality significantly improves action recognition.
Core Problem
Existing large-scale egocentric datasets (like Assembly101) rely on egocentric trackers for ground truth, which fail during severe hand-object occlusions, resulting in inaccurate pose annotations.
Why it matters:
- Inaccurate ground truth limits the ability to train robust egocentric pose estimators
- Hand pose is a critical cue for understanding procedural activities (e.g., 'screwing' implies a screwdriver), but its utility is capped by annotation quality
- Manual annotation of 3D poses at scale is prohibitively expensive and slow
Concrete Example:
In Assembly101, when a user holds a toy to disassemble it, their hand blocks the head-mounted camera's view. The original tracker guesses the hand depth incorrectly or loses track entirely, generating 'ground truth' that is anatomically impossible.
Key Novelty
Multi-View Exocentric Annotation Network (MVExoNet) with Iterative Refinement
- Leverages synchronized multi-view 'third-person' (exocentric) cameras to resolve occlusions that blind the 'first-person' (egocentric) camera
- Projects 2D image features from multiple views into a unified 3D volumetric representation to predict 3D joint locations
- Uses an iterative refinement loop where the model's own predictions re-center the input crops and 3D volume, progressively sharpening accuracy without re-training
Architecture
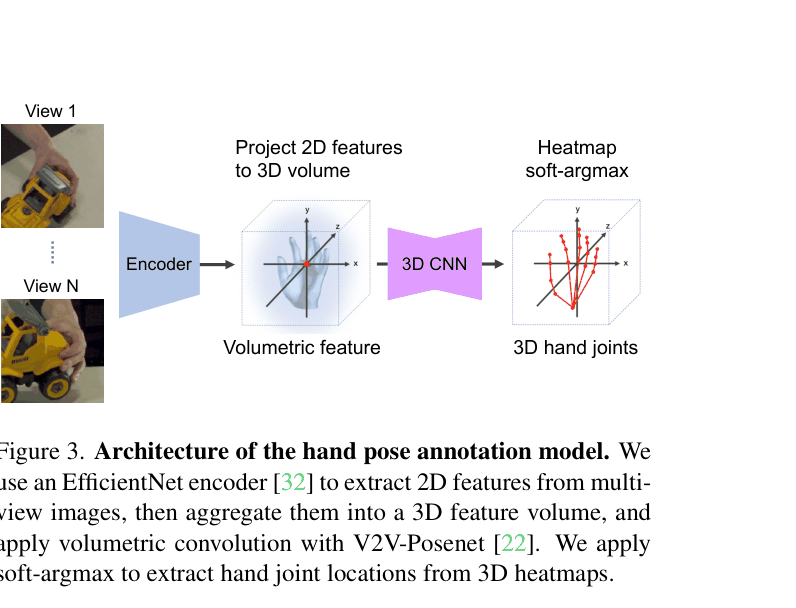
The architecture of the MVExoNet annotation model
Evaluation Highlights
- MVExoNet achieves 4.20 mm average keypoint error, an 85% error reduction compared to the original Assembly101 annotations (27.55 mm)
- Provides 3.0M annotated images (490K egocentric), making it the largest benchmark for egocentric 3D hand pose
- Action classification using poses from the proposed SVEgoNet (Single-View Egocentric Network) improves accuracy by 4.4% absolute compared to using the original UmeTrack poses
Breakthrough Assessment
8/10
Significant contribution to dataset scale and quality. The auto-annotation pipeline effectively solves the occlusion problem in egocentric vision, and the experiments crucially link pose quality to downstream action recognition.