📝 Paper Summary
FPGA/ACAP Acceleration
Hardware-Software Co-design
Deep Learning Inference
CHARM improves deep learning inference on Versal ACAP platforms by partitioning hardware resources into multiple diverse accelerators that concurrently handle large and small matrix multiplications, avoiding the inefficiency of monolithic designs.
Core Problem
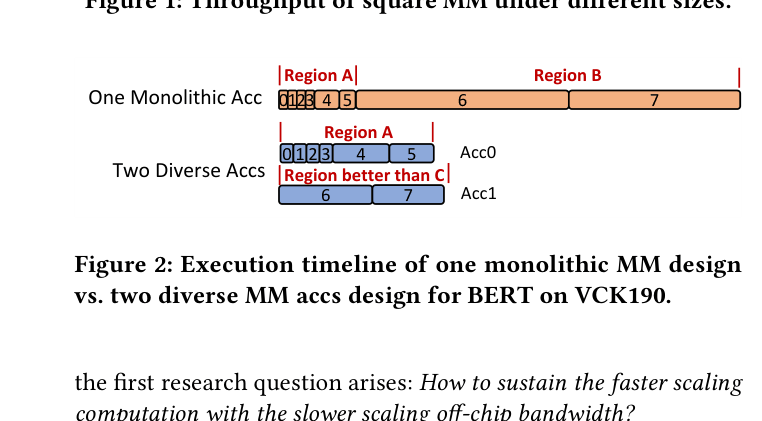
Deep learning models contain both large and small matrix multiplication layers; running small layers on a monolithic accelerator designed for large layers results in massive efficiency loss due to padding and underutilization.
Why it matters:
- Off-chip bandwidth scales slower than computation resources, requiring high on-chip data reuse which favors large tiles, but large tiles kill performance for small layers
- Real-world models like BERT have highly variable layer shapes; a single static accelerator configuration cannot optimally execute all of them
- Current approaches either waste resources via padding (monolithic) or fail to maximize data reuse for large layers (many small duplicates)
Concrete Example:
In BERT, small 'batch dot' layers constitute only 8% of operations but consume 88% of execution time on a monolithic accelerator because the 512x512x64 shapes must be padded to the accelerator's native 1536x128x1024 tile size, achieving <5% peak performance.
Key Novelty
Composing Heterogeneous Accelerators (CHARM)
- Instead of one monolithic accelerator, the framework generates a system with 'diverse' accelerators (e.g., one huge, one small) co-existing on the same chip
- Analytical modeling (CDAC) automatically partitions AIE cores, PL logic, and bandwidth between these accelerators based on the specific distribution of layer shapes in the target model
- A runtime scheduler dynamically dispatches layers to the accelerator best suited for their shape (large layers to large acc, small layers to small acc) to maximize global throughput
Architecture
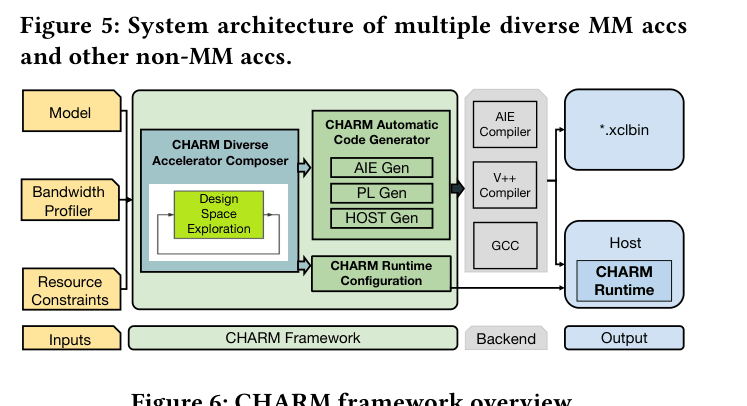
System architecture of the CHARM diverse MM accelerators design on Versal ACAP
Evaluation Highlights
- 5.29x throughput gain (1.46 TFLOPs) for BERT inference on VCK190 compared to a highly optimized monolithic accelerator baseline
- 32.51x throughput gain (1.61 TFLOPs) for Vision Transformer (ViT) inference, which is dominated by irregular small matrix shapes
- 94.7% computational efficiency achieved on single AI Engine cores for 32x32x32 matrix multiplication blocks
Breakthrough Assessment
8/10
Significant practical breakthrough for deploying Transformers on ACAP. The gain for irregular workloads (ViT) is massive. White-box open-source release adds high value for the hardware community.