📝 Paper Summary
Visual Foundation Models
Multi-Modal Sensor Fusion
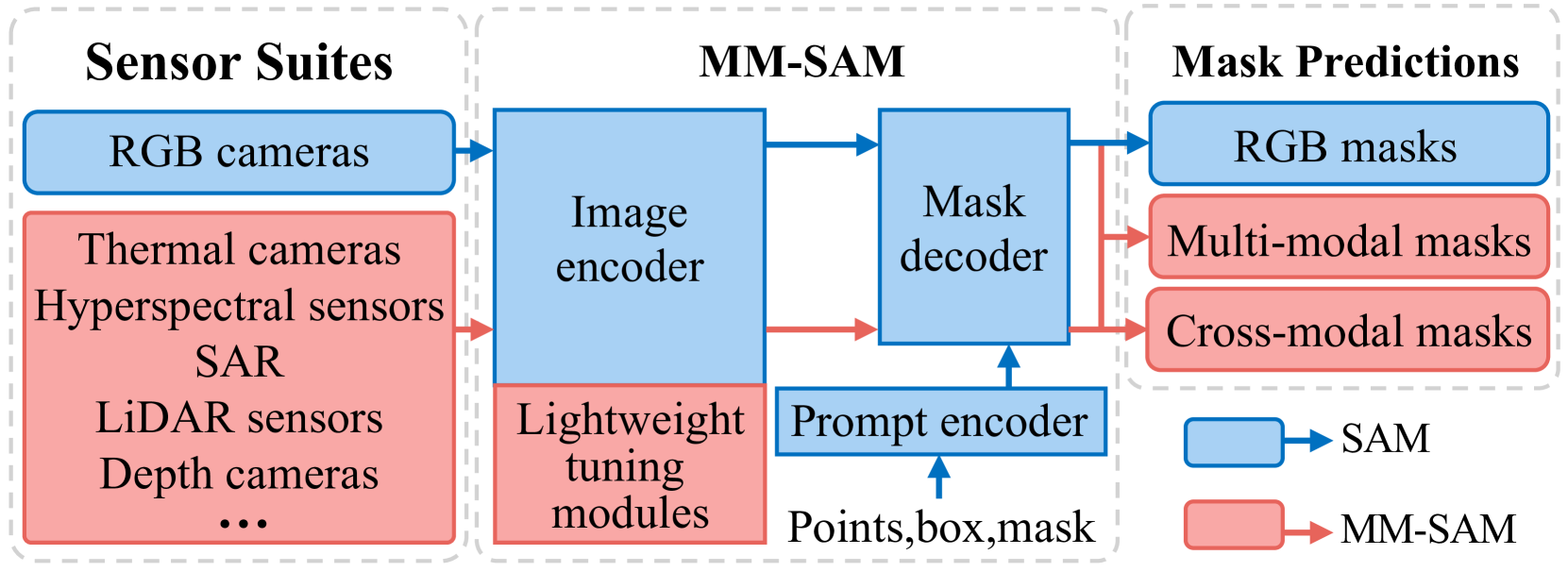
MM-SAM adapts the pre-trained Segment Anything Model (SAM) to handle non-RGB sensors and fuse multi-modal data using lightweight, label-efficient modules without requiring ground-truth mask annotations.
Core Problem
The Segment Anything Model (SAM) is trained on RGB images and struggles with non-RGB sensor data (like LiDAR or depth) or multi-modal sensor suites, limiting its use in robotics and remote sensing.
Why it matters:
- Robotics and autonomous vehicles rely on diverse sensor suites (LiDAR, thermal, depth) for robust perception, not just RGB cameras.
- Existing methods to adapt SAM often require labor-intensive mask annotations for new modalities or rely on suboptimal data transformation (e.g., false-color images) that loses information.
- Re-training SAM from scratch on new modalities is computationally prohibitive and limited by the scarcity of large-scale non-RGB datasets.
Concrete Example:
When a standard SAM model is prompted with a point on a thermal image of a pedestrian at night, it may fail to segment the person because it only understands optical features. MM-SAM aligns the thermal features to SAM's RGB latent space, allowing successful segmentation without retraining the core model.
Key Novelty
Unsupervised Cross-Modal Transfer (UCMT) and Weakly-supervised Multi-Modal Fusion (WMMF)
- Adapts SAM's image encoder to non-RGB data by forcing the new sensor's embeddings to statistically align with SAM's original RGB embedding space (Unsupervised Cross-Modal Transfer).
- Introduces a Selective Fusion Gate that learns to weight and combine features from multiple sensors (e.g., RGB + Depth) based on confidence, trained only using geometric prompts rather than full masks (Weakly-supervised Multi-Modal Fusion).
Architecture
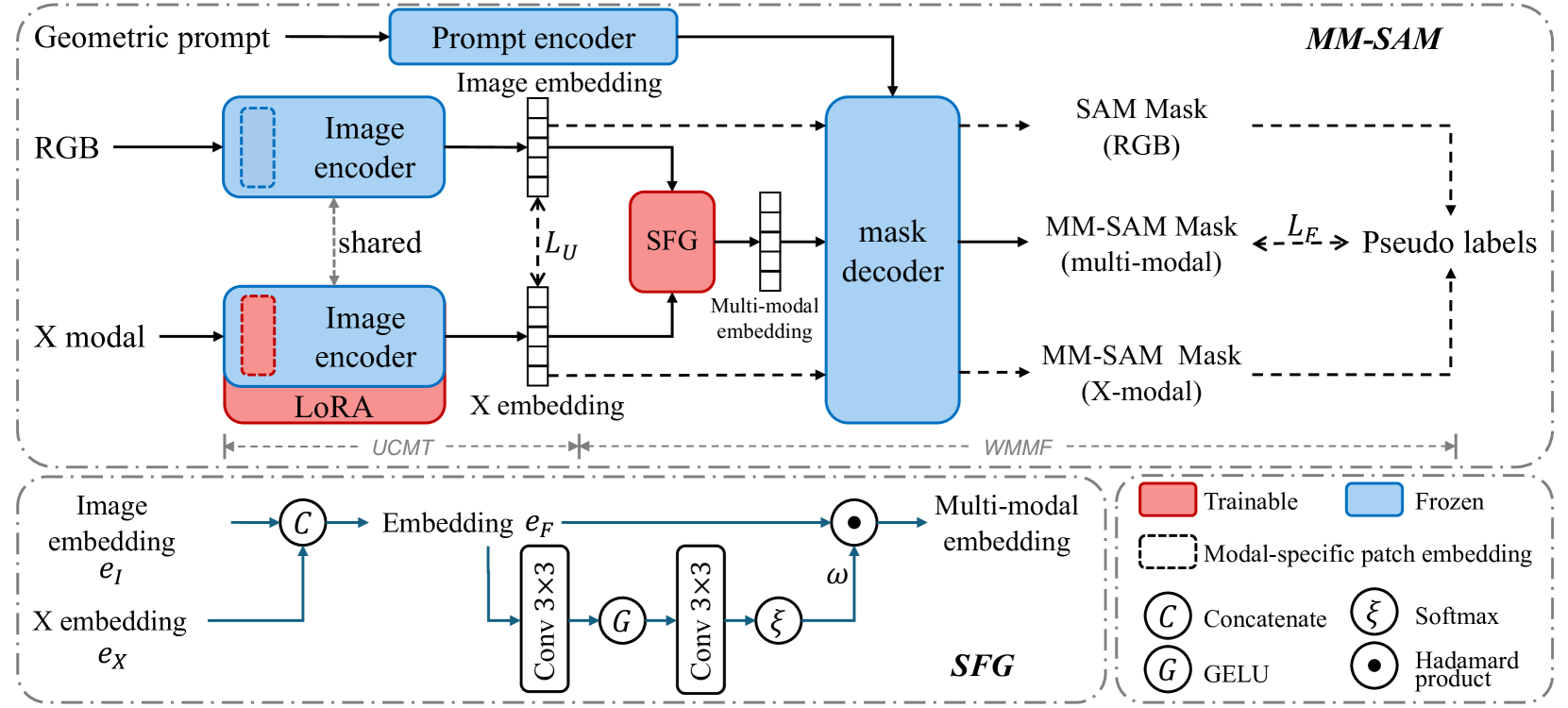
The overall architecture of MM-SAM, illustrating the two-stage pipeline: Unsupervised Cross-Modal Transfer (UCMT) and Weakly-supervised Multi-Modal Fusion (WMMF).
Evaluation Highlights
- Outperforms standard SAM by +17.5% IoU on RGB-Thermal segmentation tasks (on VT5000 dataset) using the proposed fusion.
- Achieves superior performance on depth (SUN-RGBD) and LiDAR (KITTI) modalities compared to vanilla SAM, with gains of +6.9% and +28.3% IoU respectively.
- Requires only ~0.05% additional trainable parameters compared to the original SAM model, demonstrating extreme parameter efficiency.
Breakthrough Assessment
8/10
Significantly expands SAM's applicability to robotics and remote sensing without requiring expensive mask annotations, addressing a major bottleneck in deploying foundation models to real-world sensor suites.