📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Vision Encoders
Multimodal Benchmarking
Pixtral 12B combines a 400M-parameter vision encoder trained from scratch with a 12B language decoder, using novel 2D rotary embeddings to process images at native resolution and aspect ratio.
Core Problem
Existing multimodal models typically resize or tile images into fixed squares (e.g., 224x224), destroying aspect ratio information and limiting performance on fine-grained tasks like charts or documents.
Why it matters:
- Fixed-resolution resizing forces users to choose between losing detail (downsampling) or incurring high latency (tiling), regardless of the image's actual content
- Current multimodal benchmarks rely on under-specified prompts and exact-match metrics, which penalizes correct answers with slightly different formatting and obscures true model capability
- Many multimodal models compromise text-only performance to gain vision capabilities, making them less effective as general-purpose assistants
Concrete Example:
When processing a tall, thin receipt or a wide panoramic chart, standard models break it into square tiles or squash it to a square. Pixtral processes the image at its natural dimensions using variable token counts.
Key Novelty
Pixtral-ViT with RoPE-2D (2D Rotary Positional Embeddings)
- Replaces standard learned absolute position embeddings with relative 2D rotary embeddings, allowing the vision encoder to handle any image size or aspect ratio without interpolation
- Integrates image data into the decoder via a custom adapter (MLP) that treats image tokens exactly like text tokens, enabling seamless multi-image, multi-turn conversations
- Introduces 'Explicit' prompting protocols that specify output formats in the prompt, reducing false negatives in evaluation where models answer correctly but in the wrong format
Architecture
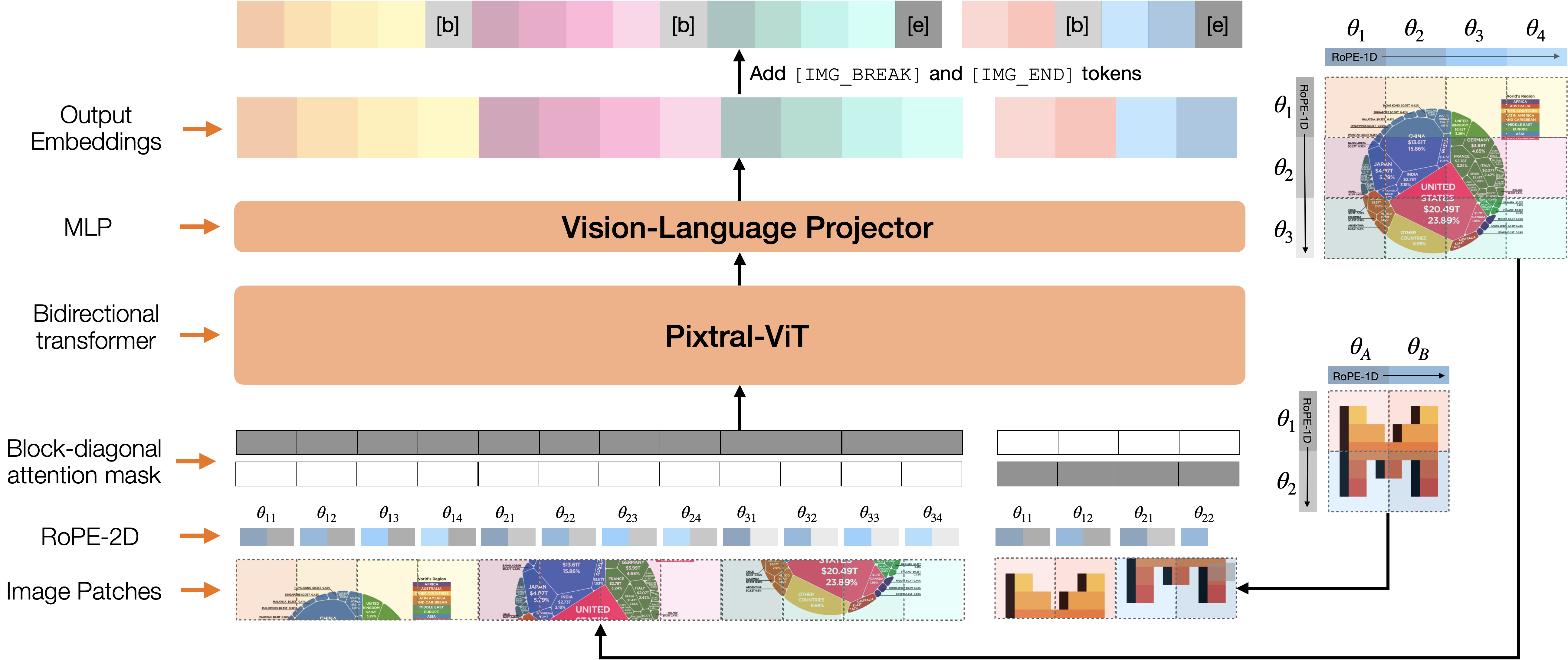
The architectural layout of Pixtral 12B, illustrating how the vision encoder and language decoder are connected.
Evaluation Highlights
- Outperforms Llama-3.2 90B on MMMU and MathVista benchmarks despite being 7x smaller (e.g., +2.3% on MMMU val vs Llama-3.2 90B)
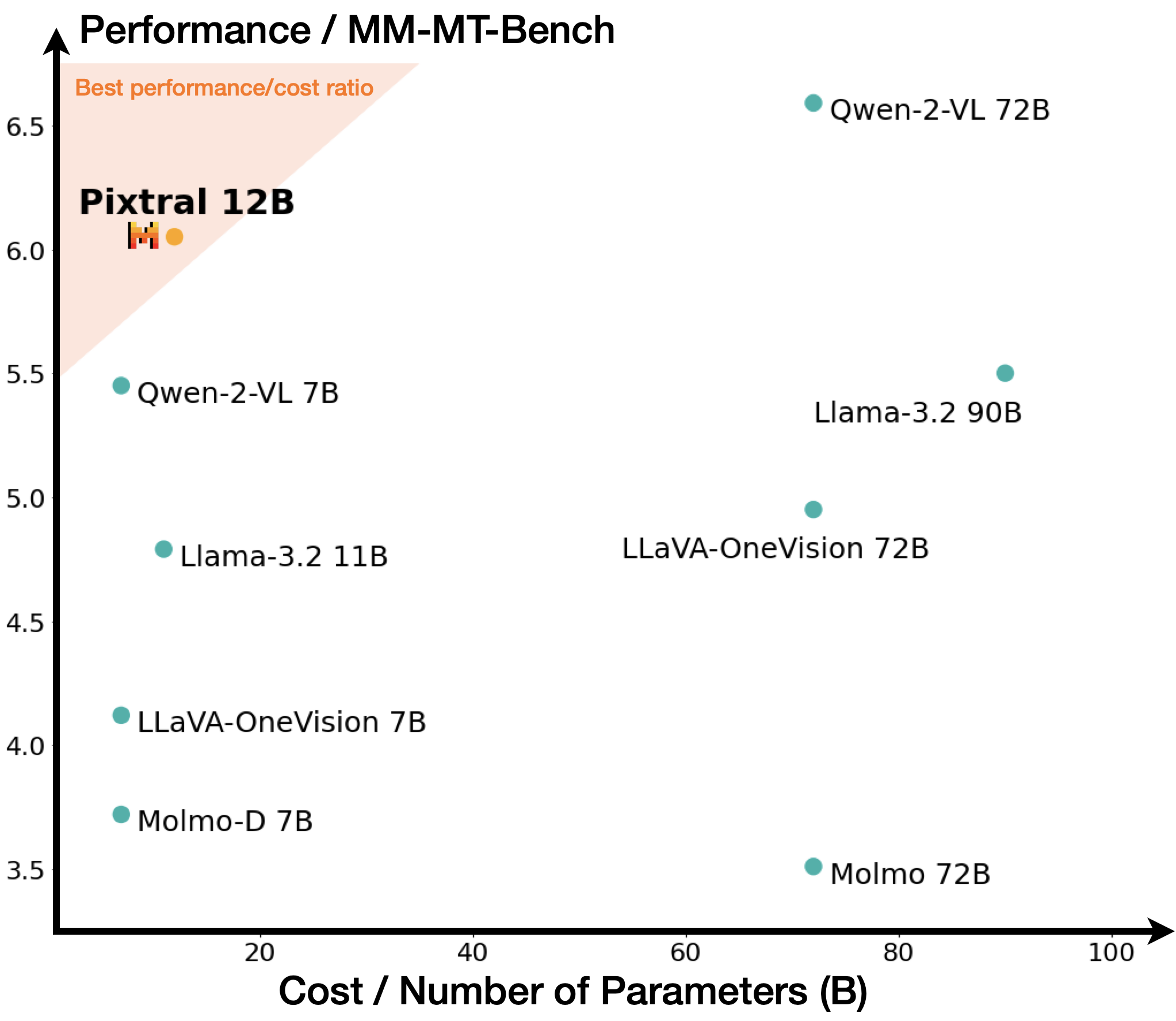
- Surpasses Qwen2-VL 7B and Llama-3.2 11B on the newly introduced MM-MT-Bench, which correlates highly (0.91) with LMSys human preference ratings
- Maintains strong text-only performance, outperforming Llama-3.1 8B on MATH (+3.7%) and HumanEval (+8.5%) benchmarks
Breakthrough Assessment
9/10
Pixtral 12B sets a new state-of-the-art for its size class by training a vision encoder from scratch that handles native resolutions, while simultaneously fixing major evaluation flaws in the field.