📝 Paper Summary
Text-guided Image Editing
Multimodal Diffusion Transformers (MM-DiT)
The paper analyzes MM-DiT attention maps to identify self- and cross-attention equivalents, proposing a robust prompt-based editing method that modifies image input projections in specific, low-noise transformer blocks.
Core Problem
Existing prompt-based editing methods designed for U-Net architectures fail on MM-DiT because MM-DiT uses a unified, bidirectional attention mechanism where text and image tokens are concatenated, unlike U-Net's separate cross-attention.
Why it matters:
- MM-DiT models like Stable Diffusion 3 and Flux.1 are replacing U-Nets as state-of-the-art, rendering previous editing techniques obsolete.
- Directly applying U-Net methods causes misalignment (e.g., text projection shifts) or visual artifacts due to noisy attention maps in scaled-up transformers.
- Scaling laws introduce noise in attention maps of larger models, making naive attention swapping ineffective for precise local editing.
Concrete Example:
When substituting the entire attention map in MM-DiT (like in Prompt-to-Prompt for U-Net), the text region shifts to the source branch's context. With T5 embeddings, subtle prompt differences amplify this misalignment, causing the edited image to shift significantly or lose coherence (e.g., changing 'cat' to 'dog' changes the background entirely).
Key Novelty
Input Projection-based Editing with Block Selection
- Decomposes MM-DiT's unified attention matrix into four blocks (I2I, T2T, T2I, I2T) to map them to U-Net concepts: I2I acts like self-attention (structure), T2I acts like cross-attention (semantic control).
- Proposes modifying only image input projections (q_i, k_i) rather than full attention maps, preventing text projection misalignment while enabling optimized SDPA kernels.
- Identifies that larger MM-DiT models have noisy attention maps and selects only the 'top-5' cleanest blocks for mask generation to ensure precise local edits.
Architecture
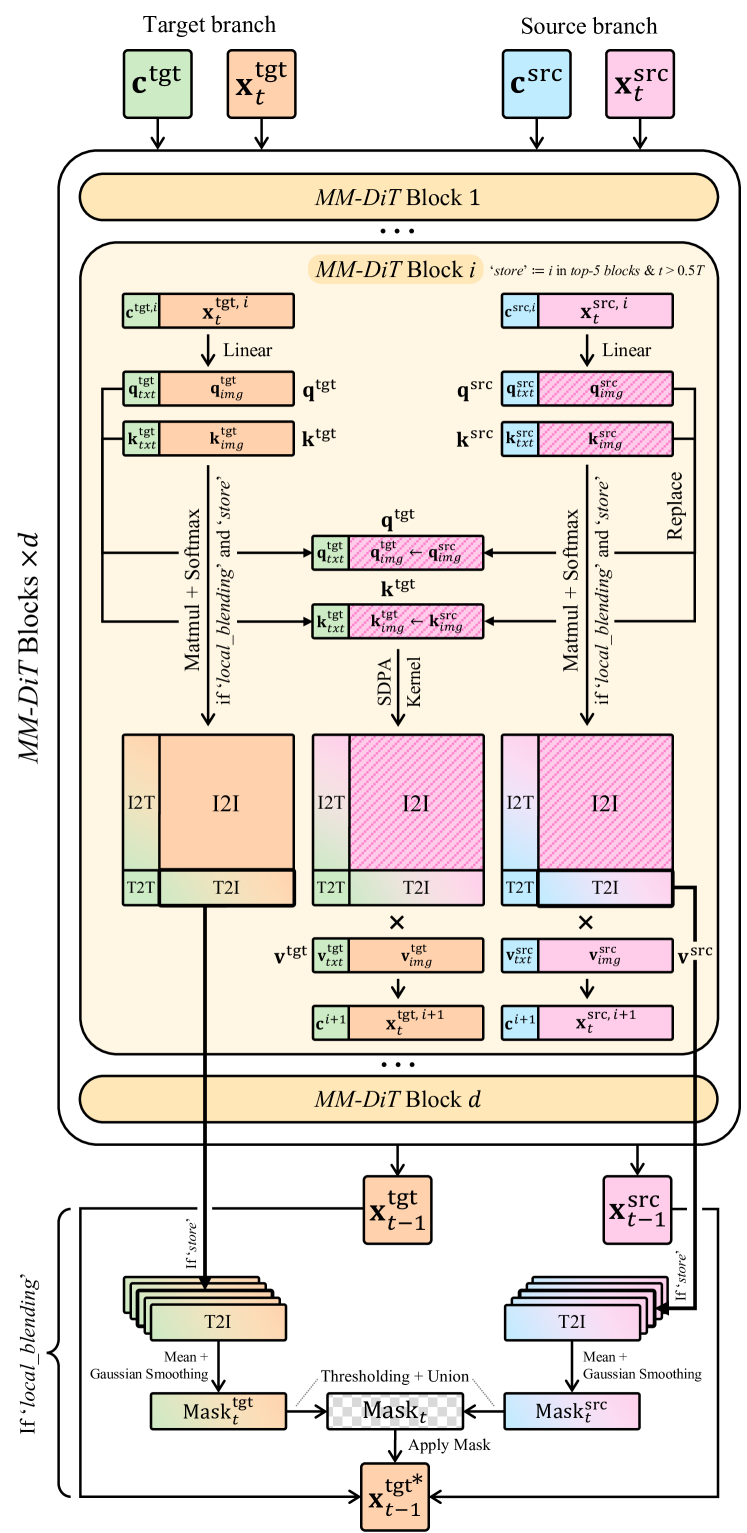
The proposed editing pipeline comparing Source and Target branches.
Evaluation Highlights
- Achieves robust editing across 5 MM-DiT variants (SD3-M, SD3.5-M/L, SD3.5-L-Turbo, Flux.1-dev/schnell) without model-specific tuning.
- Input projection modification maintains inference speed comparable to standard batch inference (SD3-M: 15.2s vs 14.9s), whereas naive attention replacement is up to 3x slower.
- Proposed 'top-5 block' selection significantly reduces artifacts compared to using all blocks, validated against Grounded SAM2 masks.
Breakthrough Assessment
7/10
Provides the first systematic analysis of MM-DiT attention for editing and a practical, efficient solution. While primarily an architectural adaptation of P2P, it solves a critical compatibility block for SOTA models.

