📝 Paper Summary
Mobile GUI Navigation
Multimodal Agents
MM-Navigator leverages GPT-4V with set-of-mark prompting to enable accurate zero-shot smartphone GUI navigation without requiring coordinate regression or task-specific training.
Core Problem
Existing GUI agents typically rely on converting screens to text (losing visual detail) or require extensive supervised training that generalizes poorly to new apps.
Why it matters:
- Supervised models trained on specific screens fail when real-world interfaces change or update
- Text-only LLM approaches lose critical spatial and visual information (layout, icons) necessary for precise navigation
- Large Multimodal Models (LMMs) understand screens but struggle to output precise numerical coordinates for execution
Concrete Example:
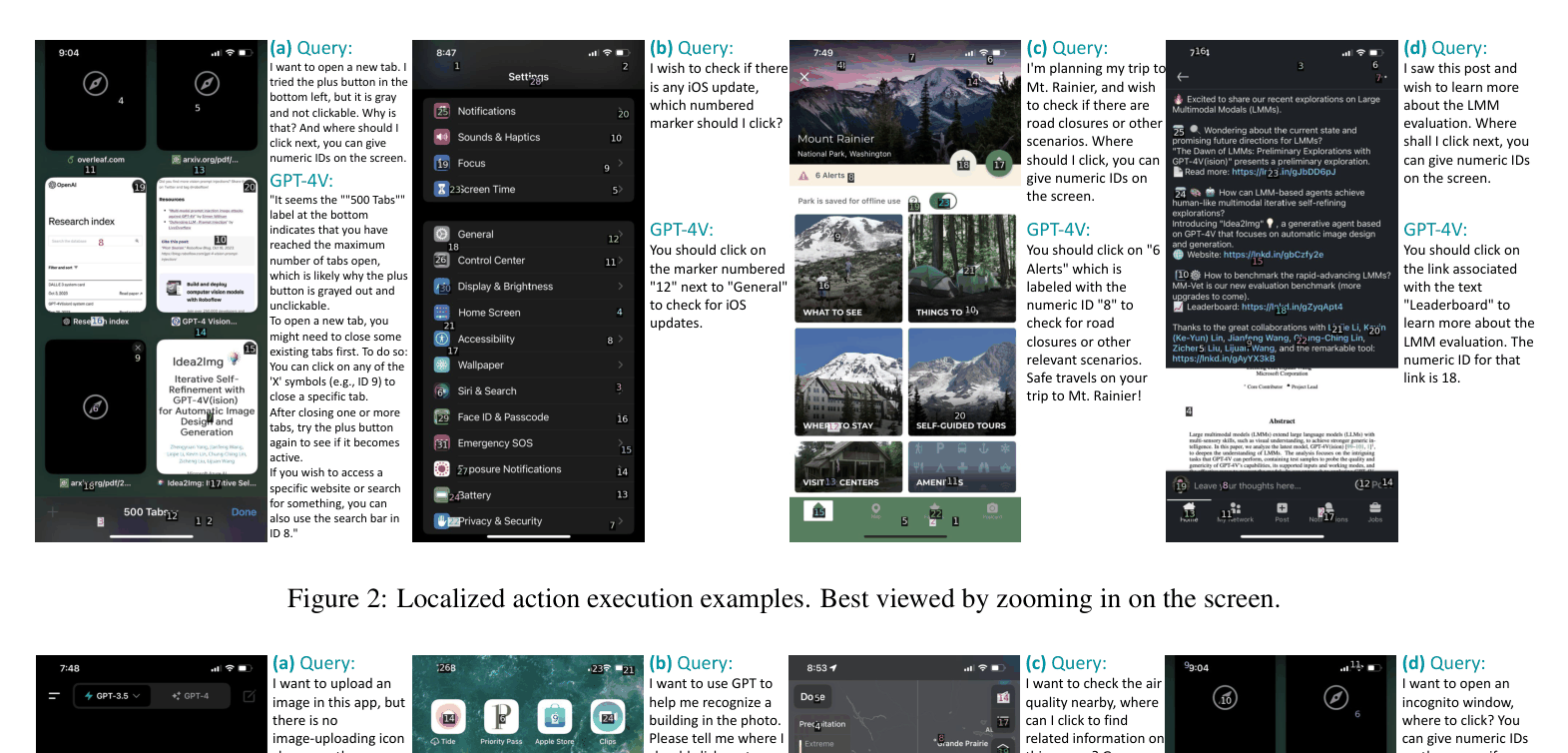
When asked to 'shop for a milk frother,' a model must click the Amazon app. A text-only model might miss the icon if not labeled in metadata. A standard LMM might identify the icon but fail to output the exact (x,y) tap coordinates. MM-Navigator overlays a numeric tag (e.g., '16') on the icon, allowing the model to simply output 'Click 16'.
Key Novelty
MM-Navigator (GPT-4V + Set-of-Mark)
- Visual Grounding via Tags: Instead of predicting coordinates, the system overlays numeric tags on all interactive elements (Set-of-Mark) and asks GPT-4V to select the correct ID
- Multimodal Self-Summarization: To handle memory without processing a long video history, GPT-4V generates a natural language summary of the previous action and screen state at each step
Architecture

The MM-Navigator inference pipeline
Evaluation Highlights
- Achieves 75% accuracy in localized action execution on a new iOS dataset, verifying zero-shot feasibility
- Outperforms supervised Fine-tuned Llama-2 by +24.56 points (52.96% vs 28.40%) on the AITW Android benchmark
- Surpasses 5-shot PaLM-2 by +13.36 points (52.96% vs 39.60%) on AITW without any training examples
Breakthrough Assessment
8/10
Establishes a strong zero-shot baseline for GUI navigation using LMMs, significantly outperforming prior supervised and text-based methods. Simplifies the action space problem effectively.