📝 Paper Summary
Autonomous Driving
Multi-Modal Large Language Models (MM-LLMs)
Long-tail Event Handling
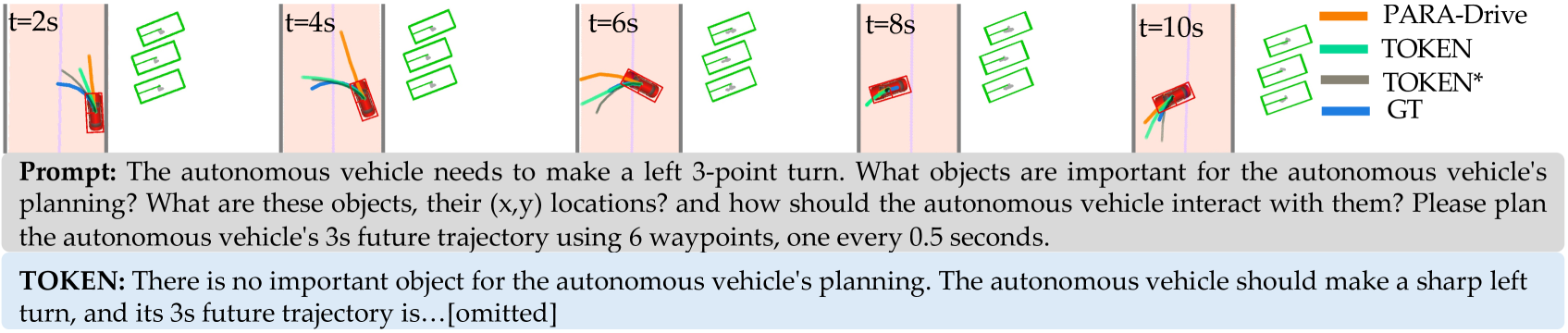
TOKEN improves autonomous driving in rare scenarios by using a pre-trained driving model to convert visual data into structured object-level tokens that an LLM can effectively reason about.
Core Problem
End-to-end driving models degrade significantly in long-tail scenarios due to data scarcity, while existing Multi-Modal LLMs lack sufficient grounding and 3D understanding because they rely on unstructured, inefficient visual tokens.
Why it matters:
- State-of-the-art end-to-end planners frequently fail in rare but critical situations like construction sites or jaywalking incidents
- Standard visual-text alignment in MM-LLMs (like CLIP) does not capture the 3D spatial and dynamic information required for safe vehicle motion planning
- Rule-based planners often outperform high-capacity neural models in these edge cases, highlighting a gap in the reasoning capabilities of learned systems
Concrete Example:
In a construction zone, a standard end-to-end planner (PARA-Drive) fails to recognize the blockage and predicts a path that collides with barriers, whereas TOKEN identifies the obstruction and plans a safe detour.
Key Novelty
Object-Centric Scene Tokenization via End-to-End Driving Model
- Instead of using generic vision encoders (like ViTs) that produce unstructured patches, the system uses a frozen, pre-trained end-to-end driving model (PARA-Drive) to extract structured tokens representing specific objects (tracks), motion, and map elements.
- These object-level tokens are condensed and semantically rich, making them easier for the LLM to interpret and reason over compared to dense grid features.
- Aligns these embodied tokens with the LLM's text space through a multi-stage training process involving perception, reasoning, and planning tasks.
Architecture
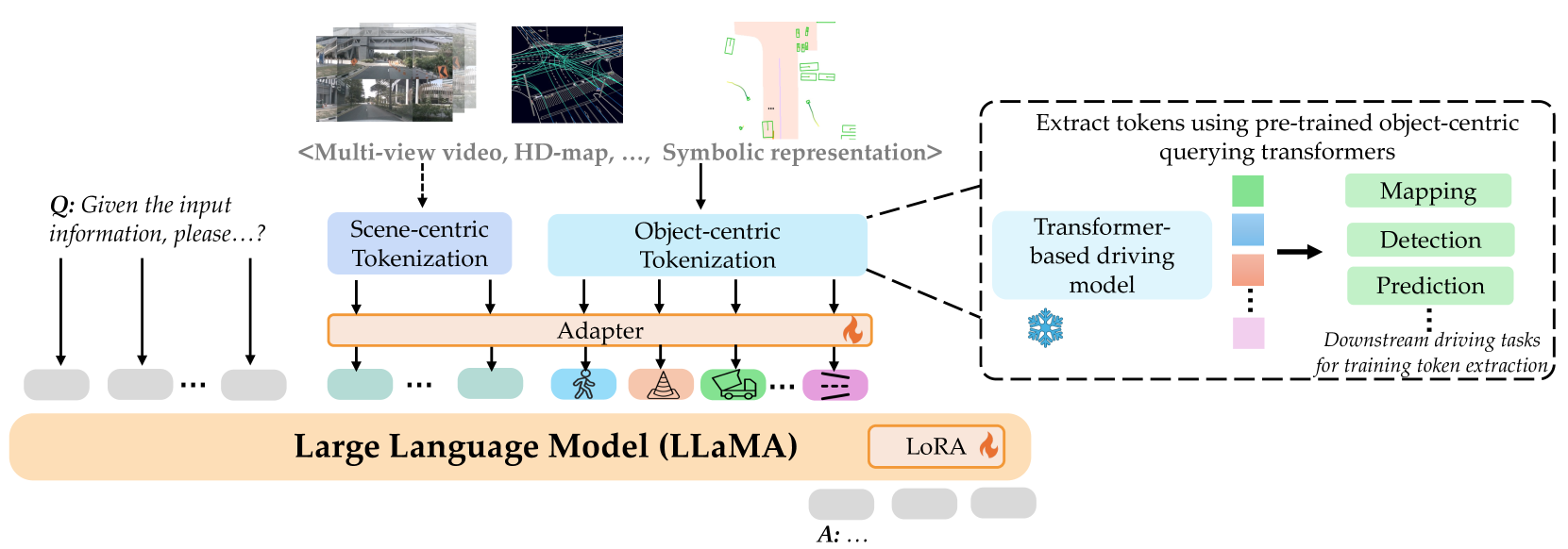
The TOKEN framework pipeline showing how sensory inputs are processed into a driving plan.
Evaluation Highlights
- 27% reduction in trajectory L2 error compared to existing frameworks in long-tail scenarios
- 39% decrease in collision rates overall in long-tail scenarios compared to baselines
- 100% reduction in collision rate during oncoming lane overtaking and 67% reduction in construction zones compared to the PARA-Drive baseline
Breakthrough Assessment
8/10
Significantly improves safety in critical long-tail driving scenarios by successfully bridging the gap between specialized driving representations and general LLM reasoning.