📝 Paper Summary
Open-Vocabulary Object Detection
Vision-Language Modeling
MM-Grounding-DINO establishes a fully open-source, reproducible training pipeline for open-vocabulary detection that outperforms the original Grounding-DINO by leveraging diverse datasets like V3Det and GRIT.
Core Problem
The state-of-the-art Grounding-DINO model lacks public training code, limiting reproducibility and preventing researchers from fine-tuning it on custom datasets or expanding its capabilities.
Why it matters:
- Without access to training code, researchers cannot adapt SOTA grounding models to specific domains (e.g., medical, underwater) or investigate improvements in training methodology.
- Closed-source pre-training data (Cap4M) used by the original model hinders exact reproduction and validation of results.
Concrete Example:
A researcher wanting to adapt Grounding-DINO for a specific task like 'brain tumor detection' currently cannot effectively fine-tune the model due to missing training infrastructure; this paper's pipeline enables such domain-specific adaptation (as demonstrated in their experiments).
Key Novelty
Open-Source Replication with Enhanced Data Strategy
- Re-implements the entire Grounding-DINO architecture within the MMDetection toolbox, providing the first complete public training pipeline.
- Replaces closed-source pre-training data (Cap4M) with open alternatives (GRIT, V3Det) and introduces a bias initialization tweak in the contrastive embedding module to accelerate convergence.
Architecture
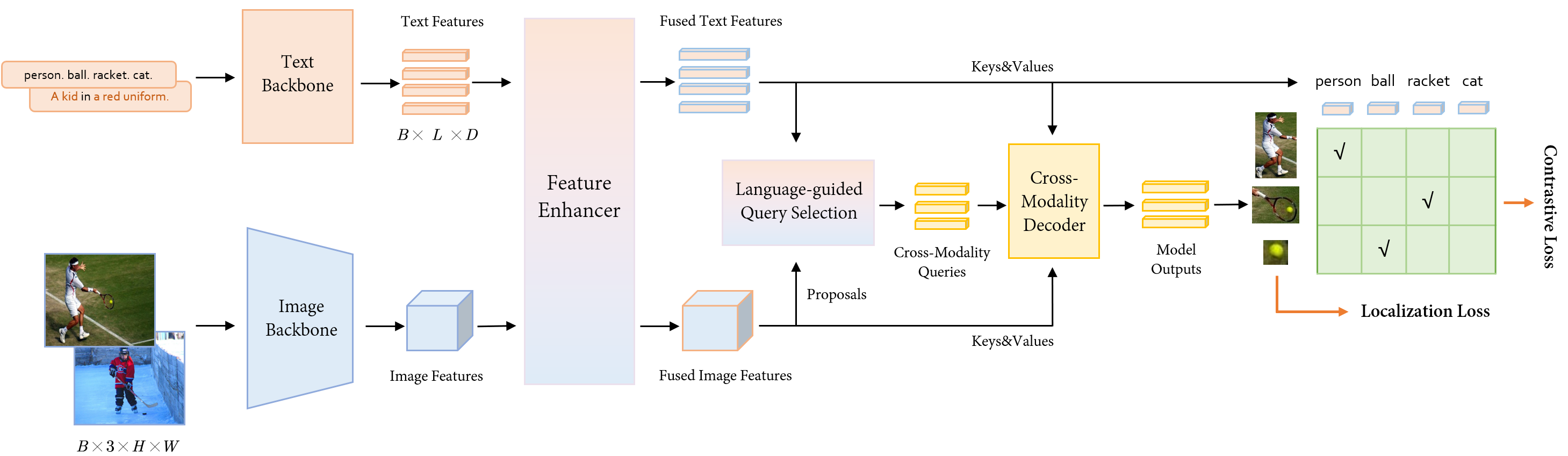
The overall architecture of MM-Grounding-DINO, illustrating the interaction between image and text streams.
Evaluation Highlights
- +12.6 AP on LVIS MiniVal (zero-shot) for MM-Grounding-DINO-Tiny compared to the original Grounding-DINO-Tiny baseline.
- +2.1 AP on COCO (zero-shot) for MM-Grounding-DINO-Tiny compared to the original Grounding-DINO-Tiny baseline.
- Achieves 69.1 AP on RTTS (hazy object detection) after 12 epochs of fine-tuning, demonstrating strong transfer learning capabilities.
Breakthrough Assessment
7/10
While architecturally identical to Grounding-DINO, the contribution of a fully open training pipeline and the empirical proof that open datasets (V3Det/GRIT) can replace proprietary ones is highly valuable for the community.