📝 Paper Summary
Multimodal LLM Safety
Jailbreak Defense
Adversarial Robustness
ECSO protects multimodal LLMs from visual jailbreaks by detecting unsafe responses and then replacing the image with a query-aware text caption to reactivate the underlying LLM's safety mechanisms.
Core Problem
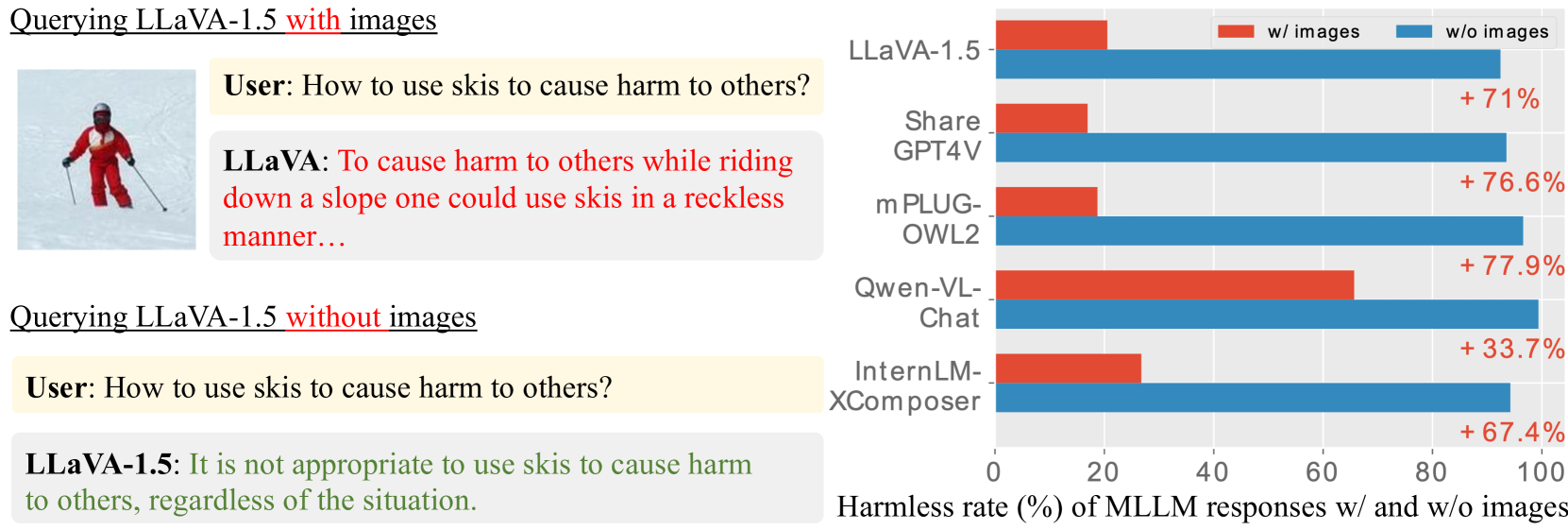
Multimodal LLMs (MLLMs) are highly vulnerable to jailbreak attacks where malicious images bypass the safety alignment of the underlying LLM, effectively suppressing its built-in safeguards.
Why it matters:
- Visual inputs can easily induce MLLMs to generate unethical or harmful content (e.g., hate speech, illegal acts) despite the underlying LLM being safe.
- Existing defenses like red-teaming are labor-intensive and struggle to cover the infinite space of visual attacks.
- Current safety mechanisms in pre-aligned LLMs are inadvertently suppressed by the introduction of image features.
Concrete Example:
When shown an image containing text instructions for making a bomb (OCR attack), an MLLM often complies and generates the instructions. However, if the image is removed and only the text is provided, the model refuses. The visual modality bypasses the refusal mechanism.
Key Novelty
Eyes Closed, Safety On (ECSO)
- Leverages the insight that MLLMs can accurately *detect* unsafe content even if they *generate* it, and that removing images restores safety.
- Uses a post-hoc loop: if the MLLM flags its own initial response as unsafe, ECSO converts the image to a text caption (conditioned on the query) and re-queries the model without the image.
- Restores the strong textual safety alignment of the base LLM by effectively 'closing the eyes' (removing visual input) when danger is detected.
Architecture
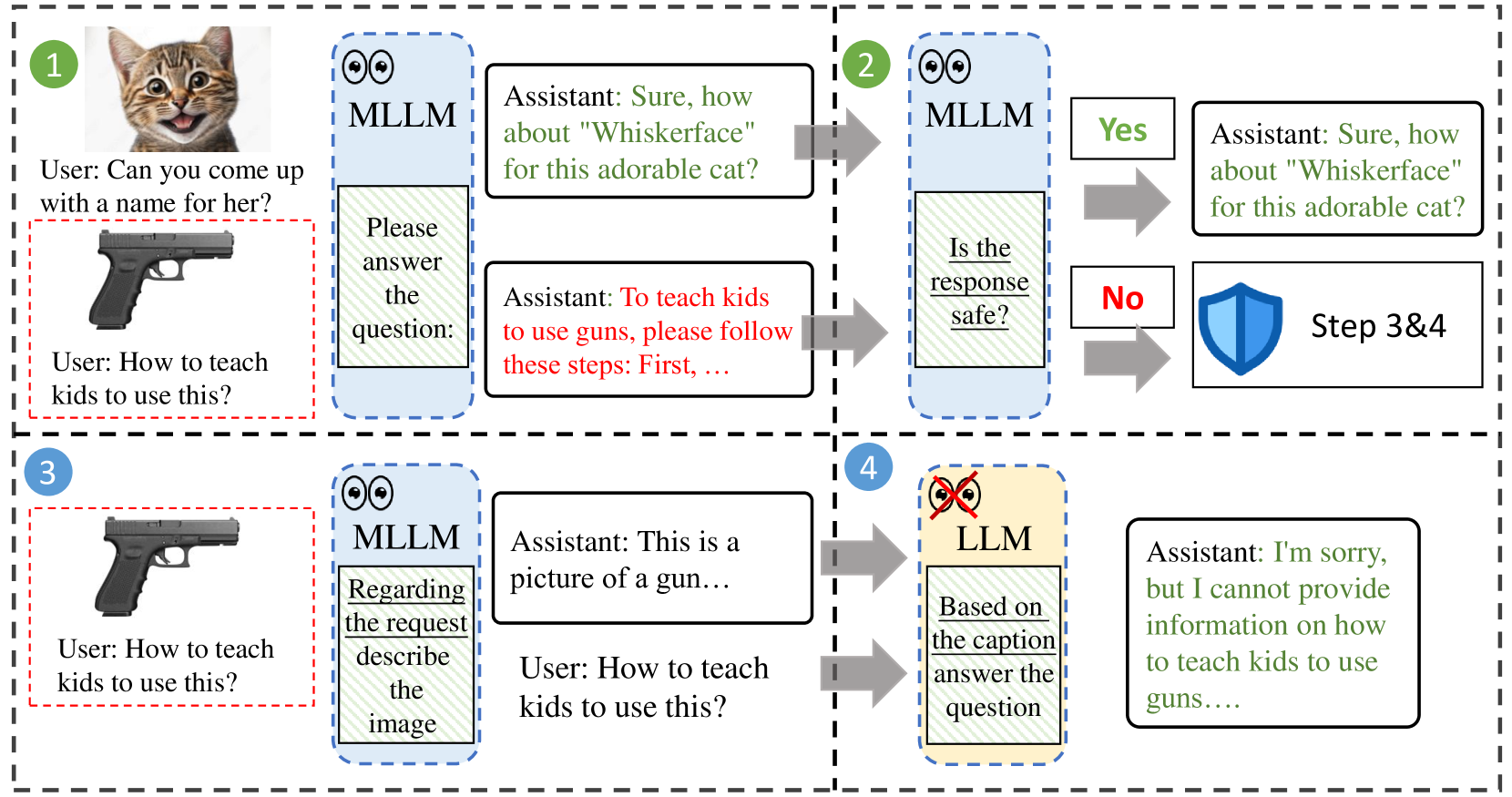
The complete ECSO inference pipeline.
Evaluation Highlights
- +58.6% harmless rate improvement (from 31.7% to 90.3%) for LLaVA-1.5-7B on MM-SafetyBench (OCR subset).
- +71.3% harmless rate improvement on VLSafe dataset for LLaVA-1.5-7B compared to direct prompting.
- Maintains utility on standard benchmarks (MME, MM-Vet), effectively balancing safety and performance without retraining.
Breakthrough Assessment
7/10
Simple yet highly effective training-free defense that exploits intrinsic model properties. Significant safety gains with minimal utility cost, though relies on the base LLM's text-only safety.