📝 Paper Summary
Visual Language Models (VLMs)
Long-Context Modeling
Distributed Training Systems
LongVILA enables visual-language models to process over one million tokens by co-designing a five-stage training pipeline and a multi-modal sequence parallelism system that handles modality and network heterogeneity.
Core Problem
Training VLMs on long videos is computationally intensive, and existing text-only parallelism techniques fail due to imbalanced workloads from image tokens (modality heterogeneity) and inefficient communication across nodes (networking heterogeneity).
Why it matters:
- Long videos (e.g., movies, hour-long footage) require processing hundreds of thousands of tokens, exceeding single-GPU memory limits.
- Existing solutions like Ring-style SP suffer from high communication latency, while DeepSpeed-Ulysses is limited by the number of attention heads.
- Simple distribution of multi-modal data leads to load imbalances because image placeholders expand into hundreds of tokens during encoding.
Concrete Example:
A single 1400-frame video sequence generates ~274k tokens. Treating image placeholder tokens like text tokens during parallelism causes some GPUs to carry significantly heavier compute loads than others (modality heterogeneity), slowing down the entire cluster.
Key Novelty
Multi-Modal Sequence Parallelism (MM-SP)
- Handles modality heterogeneity by first distributing images evenly across GPUs for encoding, then redistributing tokens for the LLM forward pass.
- Uses 2D-Attention to combine All-to-All communication (Ulysses-style) for attention heads with P2P communication (Ring-style) for sequence chunks, optimizing for both intra-node and inter-node bandwidth.
Architecture

The MM-SP workflow handling modality heterogeneity through a two-stage sharding strategy.
Evaluation Highlights
- Achieves 99.8% accuracy on 'Needle-in-a-Haystack' retrieval task with 6,000-frame videos (>1 million tokens).
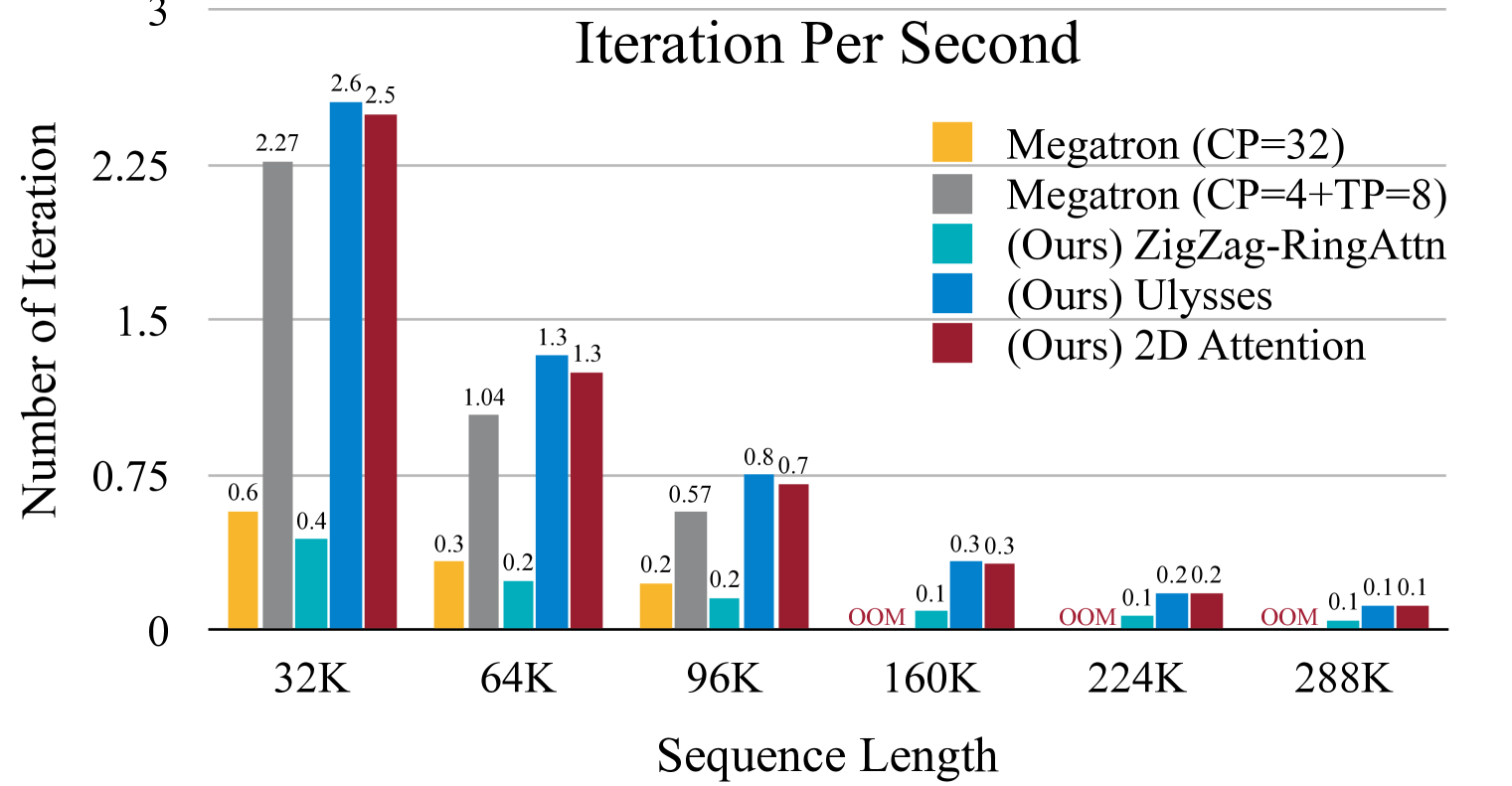
- MM-SP system achieves 2.1× to 5.7× speedup compared to Ring-style sequence parallelism.
- Scales context length to 2 million tokens on 256 GPUs without requiring gradient checkpointing.
Breakthrough Assessment
9/10
Provides a comprehensive full-stack solution (system + algorithm) that unlocks million-token scale for VLMs, addressing critical infrastructure bottlenecks that previously prevented long-video training.