📝 Paper Summary
Multimodal Large Language Models (MM-LLMs)
Multimodal Generation
NExT-GPT enables an LLM to accept and generate any combination of text, image, audio, and video by connecting frozen encoders and diffusion decoders via lightweight projection layers.
Core Problem
Most existing MM-LLMs only support multimodal input (understanding) or limited output (text+image), while systems that do both often rely on disjointed pipelines that cannot reason end-to-end.
Why it matters:
- Human communication naturally involves seamless transitions between multiple modalities (hearing, seeing, speaking), which current AI lacks
- Pipeline approaches (cascading separate tools) introduce noise and error propagation between modules
- Lack of end-to-end training limits the system's ability to interpret intricate or implicit cross-modal user instructions
Concrete Example:
Pipeline systems like Visual-ChatGPT pass information between modules using only discrete text; if the LLM generates a vague description for an image generator, the visual information is lost or distorted because the generator cannot access the original rich context.
Key Novelty
End-to-End Any-to-Any MM-LLM via Lightweight Alignment
- Connects a frozen unified encoder (ImageBind) and multiple frozen diffusion decoders to an LLM core using small learnable projection layers
- LLM generates special 'modality signal' tokens that act as instructions for the decoding layers, triggering specific diffusion models to generate content
- Uses Modality-switching Instruction Tuning (MosIT) to teach the model how to handle complex cross-modal semantic understanding and content generation
Architecture
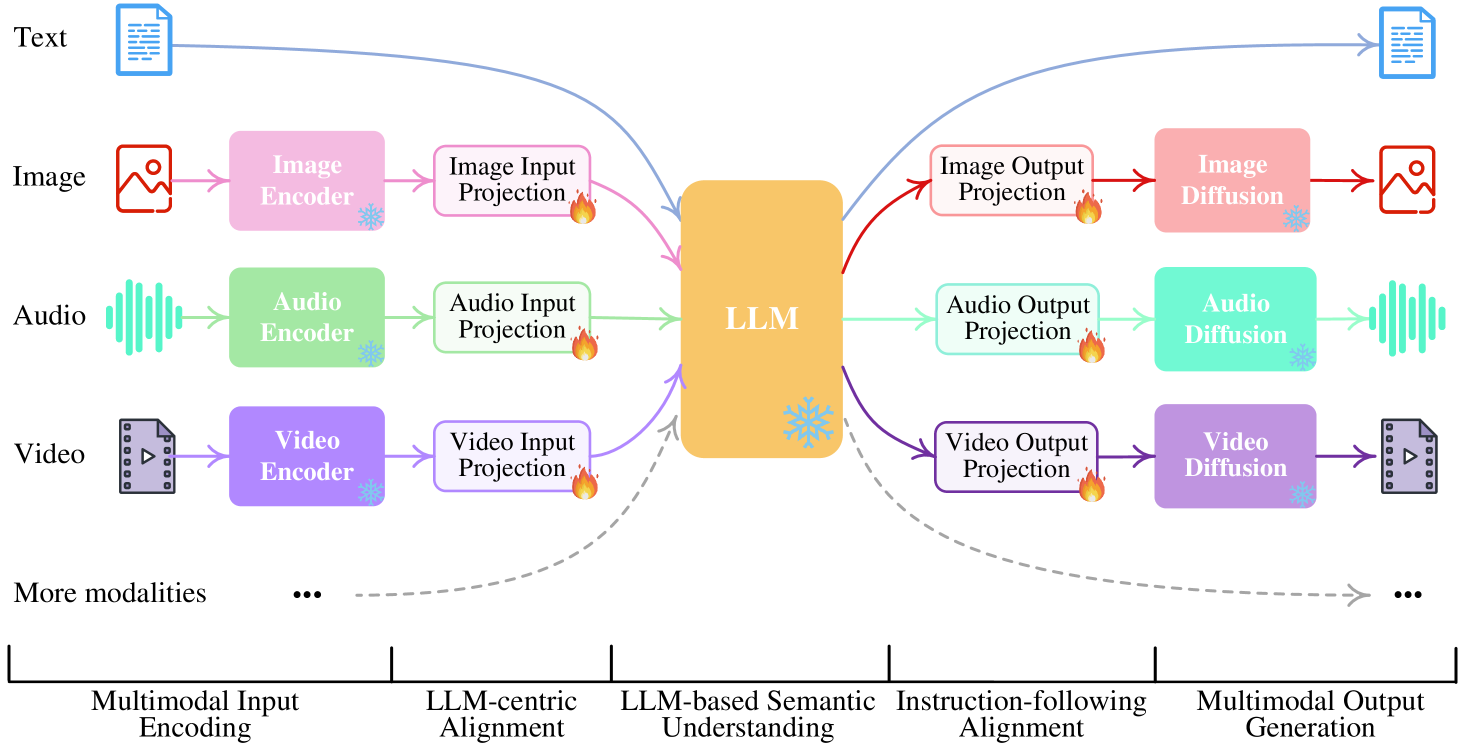
Schematic overview of the NExT-GPT framework comprising three tiers: Encoding, LLM Understanding, and Decoding.
Breakthrough Assessment
8/10
First end-to-end general-purpose any-to-any MM-LLM framework. Highly efficient design (tuning only 1% of params) effectively bridges the gap between understanding and generation across four modalities.