📝 Paper Summary
Visual Language Models (VLMs)
GUI Agents
High-Resolution Image Processing
CogAgent is an 18-billion-parameter visual language model that efficiently processes high-resolution (1120x1120) screenshots to navigate GUIs and recognize tiny text using a novel dual-encoder architecture.
Core Problem
Existing Large Language Models (LLMs) struggle with GUIs because they lack visual perception, while standard Visual Language Models (VLMs) cannot handle the high-resolution images needed to read tiny text and icons without prohibitive computational cost.
Why it matters:
- Standard VLMs often resize images to 224x224, making small GUI elements (text, icons) unreadable and preventing effective automation.
- LLM-based agents rely on HTML/accessibility trees, which are often incomplete or missing in applications like canvas, videos, or remote desktops.
- Increasing resolution naively in Transformers causes quadratic sequence length explosion (e.g., 6400 tokens), making inference too slow and expensive.
Concrete Example:
At 224x224 resolution, a 'Submit' button on a dense webpage becomes a blurry blob indistinguishable from background noise. CogAgent perceives this at 1120x1120, clearly reading the text and locating the button coordinates.
Key Novelty
High-Resolution Cross-Module
- Adds a lightweight, high-resolution visual branch (1120x1120 input) alongside the standard low-resolution branch (224x224).
- Uses a smaller hidden size for the high-res branch to capture text/edge details efficiently, fusing features via cross-attention into the main decoder layers rather than concatenating massive token sequences.
Architecture
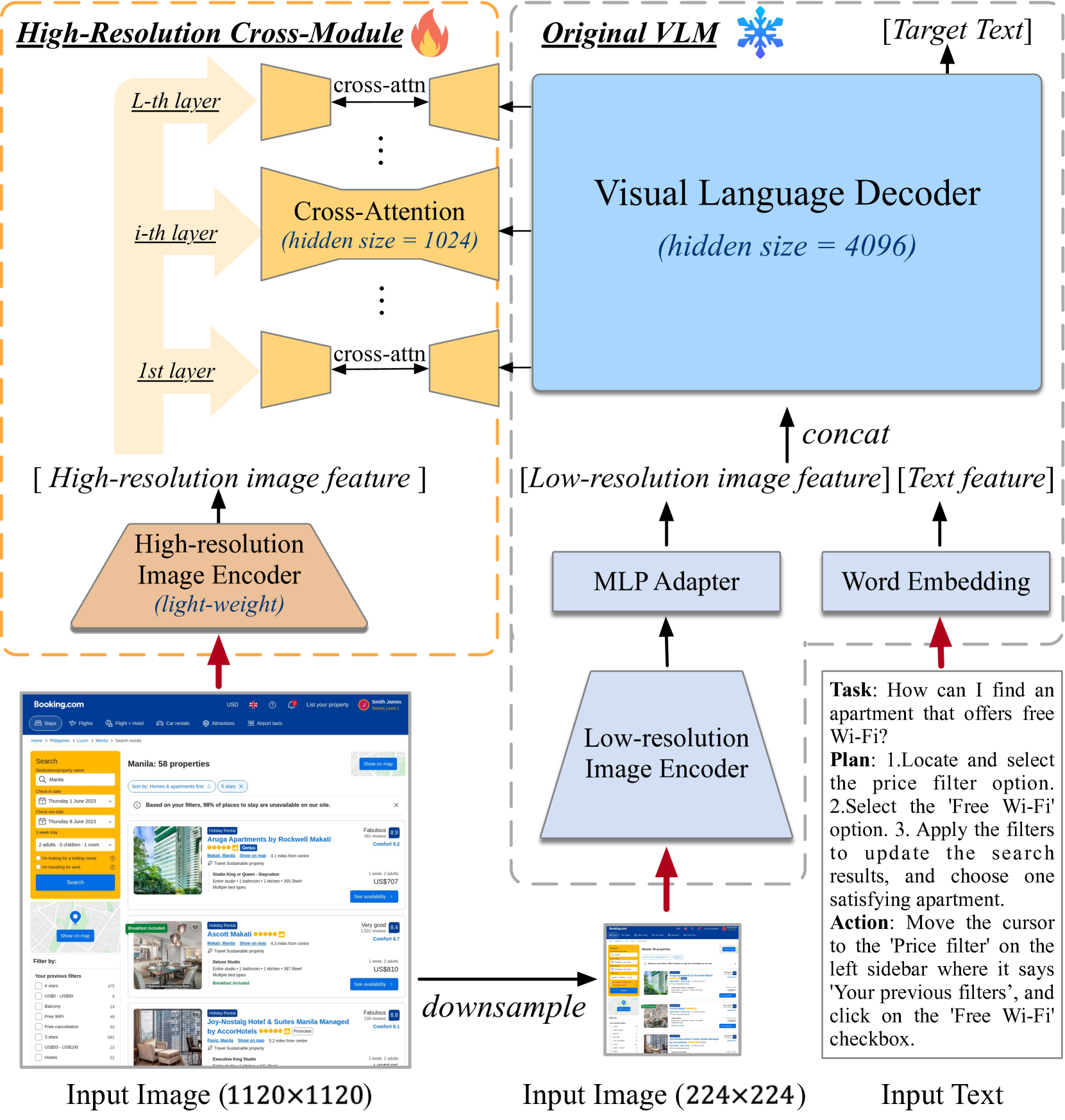
The dual-branch architecture of CogAgent. It shows how high-res and low-res images are processed separately and fused.
Evaluation Highlights
- Achieves state-of-the-art on AITW (Android In The Wild), surpassing LLM-based methods like LLM-SFT that use extracted text/HTML.
- Outperforms all VLM baselines on 9 classic VQA benchmarks, including +5.5% on TextVQA compared to CogVLM.
- Reduces FLOPs by >50% compared to scaling a standard CogVLM-17B to equivalent high resolutions (1120x1120).
Breakthrough Assessment
9/10
First generalist VLM to outperform text-based LLM agents on GUI tasks purely through visual input. The dual-resolution architecture solves a critical bottleneck in VLM scaling.