📝 Paper Summary
Language Modeling
Latent Variable Models
Reasoning/Chain-of-Thought
Latent Thought Models introduce explicit latent vectors that guide token generation, enabling a dual-rate learning process where inference-time computation improves performance without increasing model parameters.
Core Problem
Traditional Large Language Models (LLMs) rely on massive model sizes and data scaling for performance, but data availability is becoming a bottleneck and standard auto-regressive models lack explicit internal reasoning states.
Why it matters:
- Scaling laws require exponentially more data/compute for marginal gains, hitting data scarcity walls
- Current LLMs lack a separation between 'fast' episodic learning (inference-time adaptation) and 'slow' schematic learning (weight updates)
- Inference-time compute is an under-utilized dimension for scaling performance compared to just adding more parameters
Concrete Example:
In standard GPT training, the model must predict the next token immediately based on context. In LTMs, the model first performs 'fast learning' (optimization steps) to find the best latent vector *z* for the current sequence, essentially 'thinking' before generating, which allows a small 76M parameter model to match the perplexity of a 774M parameter GPT-2 Large.
Key Novelty
Latent Thought Models (LTMs) with Dual-Rate Optimization
- Introduces 'latent thought vectors' (z) that act as abstract, structured representations of a sequence, conditioning the generation of every token
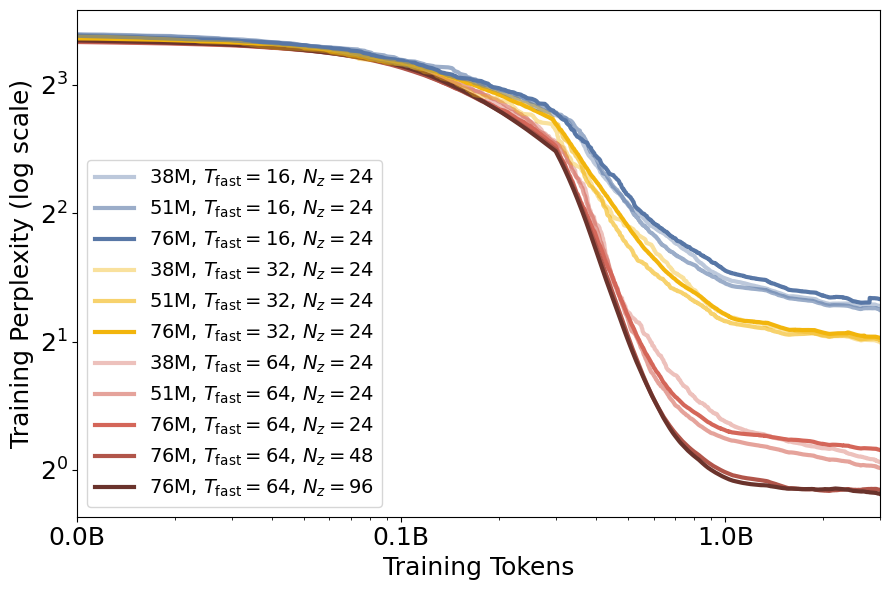
- Uses a dual-rate optimization: 'fast learning' (inference-time optimization of z per sequence) and 'slow learning' (standard gradient updates for global model weights)
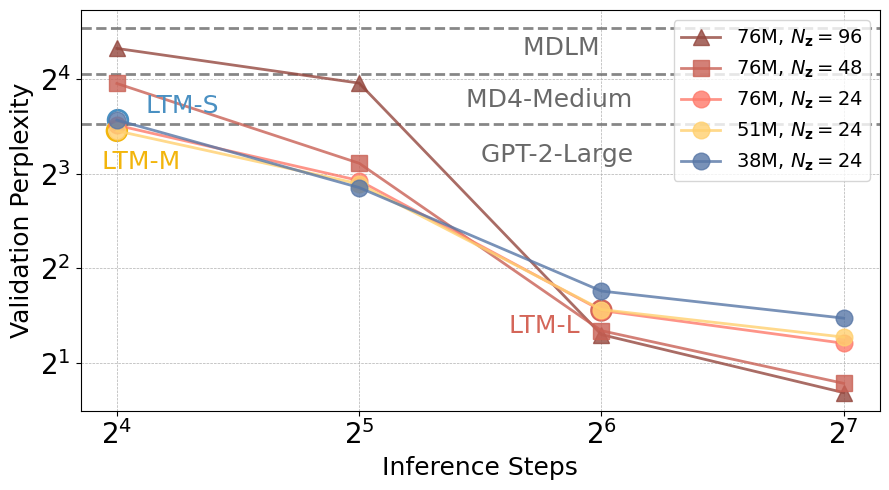
- Treats inference steps as a scaling dimension: performing more optimization steps on z during inference improves results without retraining the main model
Architecture
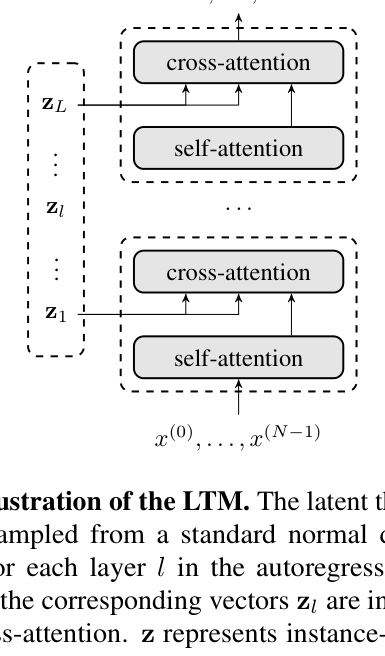
Probabilistic graphical model and architecture of LTM. Shows latent thought vectors z controlling the generation of token sequence x.
Evaluation Highlights
- LTM-Large (76M parameters) achieves 3.05 validation perplexity on OpenWebText, outperforming GPT-2 Large (774M parameters) which has ~10x more parameters
- Zero-shot language modeling perplexity reduced by 91.7% compared to state-of-the-art results at GPT-2 scale
- Demonstrates emergent few-shot in-context arithmetic reasoning in small models (e.g., LTM-Small), a capability usually reserved for much larger LLMs
Breakthrough Assessment
8/10
Proposes a fundamental architectural shift from pure autoregression to latent-guided generation with a practical inference-time compute scaling law. Strong empirical results on efficiency make it a significant contribution.