📝 Paper Summary
Video Understanding
Computational Media Understanding
Affective Computing
MM-AU introduces a large-scale multimodal dataset for advertisement understanding and demonstrates that fusing audio, visual, and text modalities improves performance on topic, tone, and social message detection.
Core Problem
Current media understanding datasets largely focus on movies or generic videos, failing to capture the condensed narrative structures, rapid tone transitions, and persuasive social messaging unique to advertisements.
Why it matters:
- Advertisements are a primary medium for social influence and product promotion, requiring distinct analysis from feature-length content
- Understanding ads requires modeling fine-grained transitions (e.g., negative-to-positive narrative arcs) which static classification misses
- Existing ad datasets are often limited to images or lack multimodal annotations for complex reasoning tasks
Concrete Example:
An ad might start with a negative tone (sad music, suffering characters) to highlight a problem like pollution, then shift to a positive tone (upbeat music, solution) to promote a brand. A standard sentiment classifier averaging the whole video would miss this crucial narrative arc.
Key Novelty
MM-AU Benchmark & Tone Transition Task
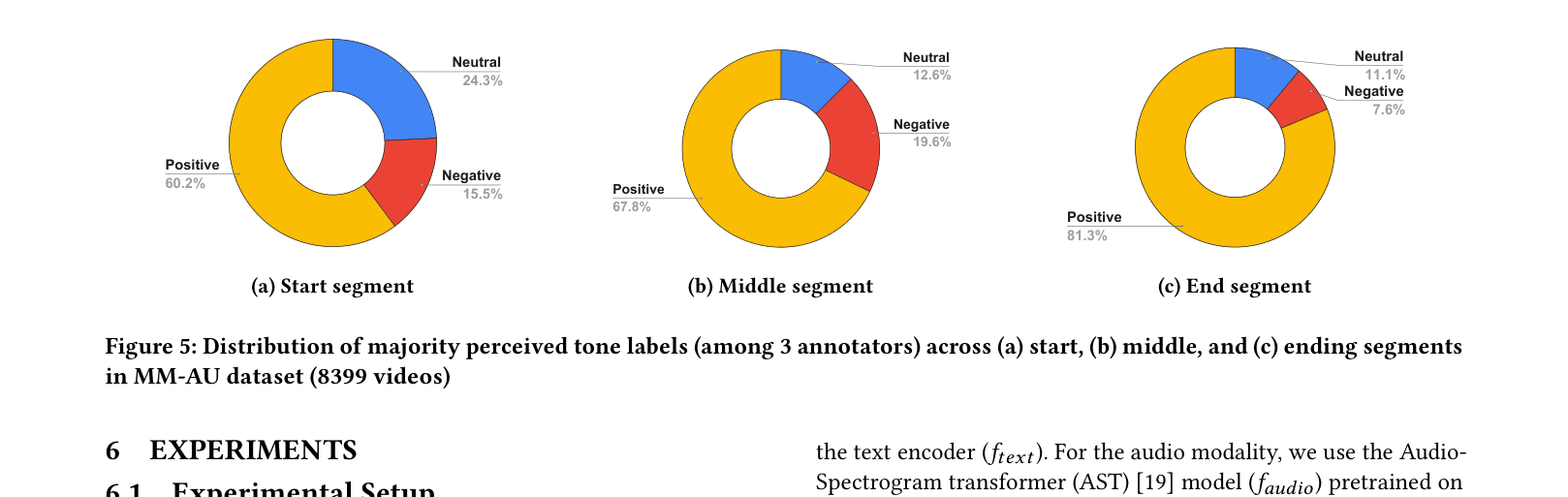
- Introduction of 'Tone Transition' as a formal task: tracking the affective shift (Start vs. Middle vs. End) within a condensed video narrative
- Curating a multilingual dataset of 8.4K videos with expert annotations for social message presence and topic categorization across 18 classes
- A two-stage multimodal fusion approach using PerceiverIO to combine Audio-Visual and Text-Visual signals for high-level semantic reasoning
Architecture
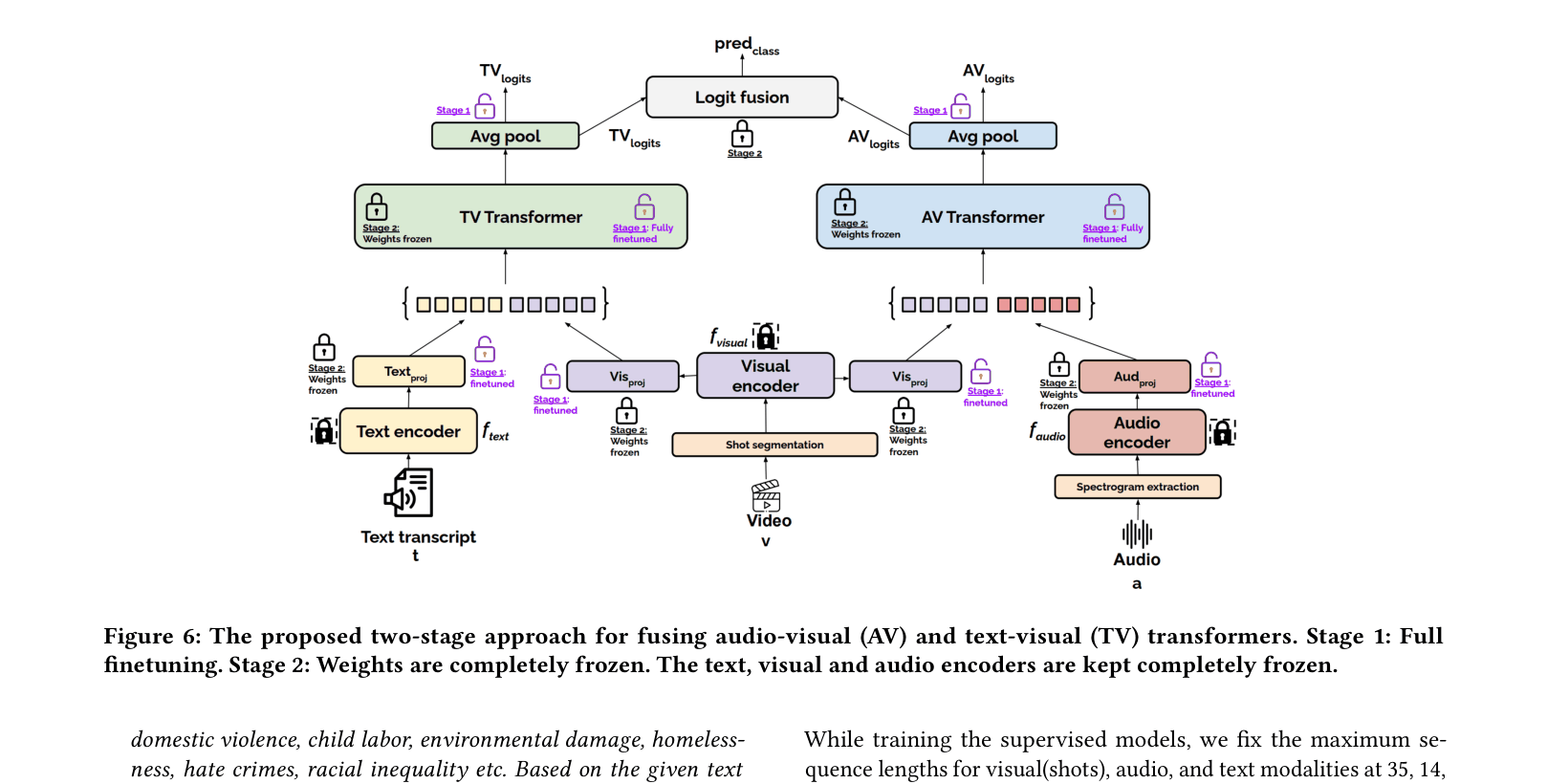
The two-stage multimodal fusion pipeline used for the benchmark tasks
Evaluation Highlights
- Proposed A-Max multimodal fusion achieves 65.92% accuracy on Topic Categorization, doubling the performance of zero-shot GPT-4 (33.29%)
- Text-Visual fusion (TxTV) proves most effective for Social Message detection (74.03% F1), significantly outperforming Audio-Visual methods (70.05% F1)
- Audio-Visual fusion is superior for Tone Transition detection (63.72% F1) compared to Text-Visual methods, highlighting the role of soundscapes in affect
Breakthrough Assessment
7/10
Strong contribution in dataset curation and defining the novel task of tone transition in ads. The modeling approach is a standard application of transformers, but the benchmark enables new research directions.