📊 Experiments & Results
Evaluation Setup
Zero-shot and few-shot evaluation across diverse vision-language tasks
Benchmarks:
- ImageNet (Zero-shot Image Classification)
- Dollar Street (Cultural/Geo-localization (Zero-shot & 10-shot))
- Crossmodal-3600 (XM3600) (Multilingual Image-Text Retrieval)
- GeoDE (Geographically Diverse Object Recognition)
Metrics:
- Top-1 Accuracy
- Recall@1
- Representation Bias (RB)
- Association Bias (AB)
- Statistical methodology: Wilcoxon's signed rank test reported for comparing model performance across scales.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Standard benchmarks show saturation or negligible gains when scaling from 10B to 100B examples. | ||||
| ImageNet (Zero-shot) | Accuracy | 80.4 | 80.6 | +0.2 |
| Cultural diversity benchmarks show significant improvements, highlighting the benefit of massive scale for long-tail concepts. | ||||
| Dollar Street (10-shot) | Accuracy | 35.9 | 41.7 | +5.8 |
| Dollar Street (10-shot) | Accuracy | Not reported in the paper | Not reported in the paper | Not reported in the paper |
| Fairness analysis reveals that scaling data does not automatically fix societal biases. | ||||
| ImageNet Gender Representation | Male Association Probability | 0.85 | 0.85 | 0.0 |
Experiment Figures
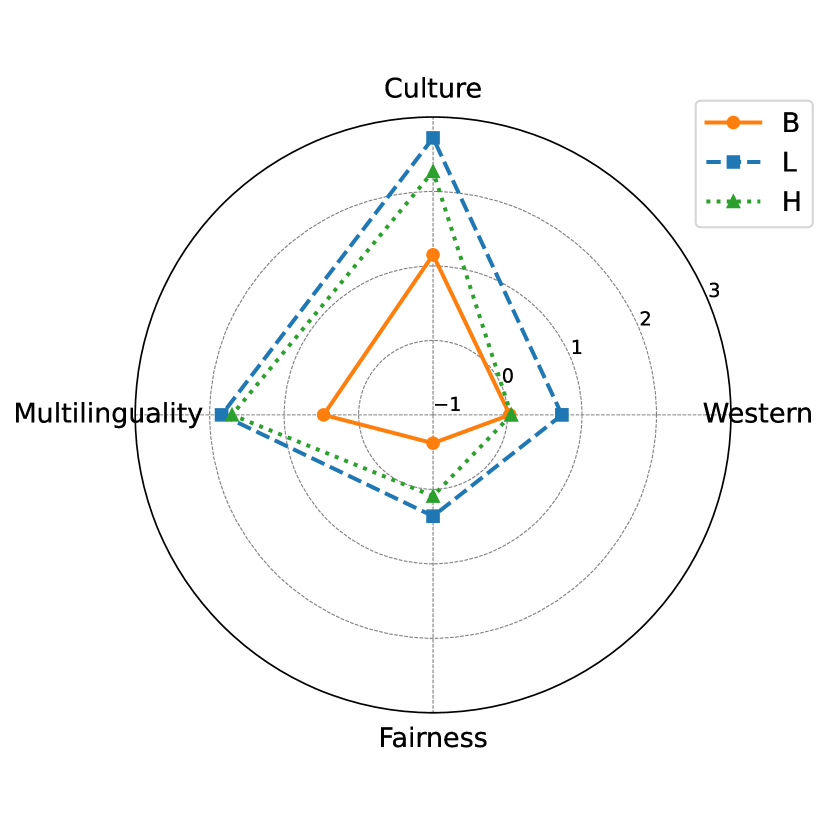
Summary of improvements in cultural diversity and multilinguality achieved through data scaling
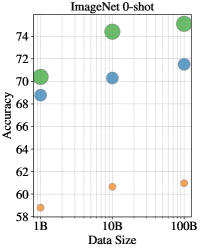
Performance disparity between high-resource and low-resource languages on Crossmodal-3600 as model size increases
Main Takeaways
- Traditional Western-centric benchmarks (COCO, ImageNet) saturate at 100B scale, suggesting they are insufficient for measuring progress in massive-scale VLP.
- Data scaling is critical for inclusivity: significant gains are observed in cultural geo-localization (Dollar Street) and low-resource languages (XM3600), where long-tail data coverage is key.
- Quality filtering (e.g., using CLIP to remove 'noisy' data) inadvertently harms cultural diversity, improving standard metrics at the cost of inclusivity.
- Societal biases (gender associations) are persistent and do not vanish with scale alone, requiring explicit mitigation strategies beyond just 'more data'.