📝 Paper Summary
Long-form video understanding
Multimodal Agents
Audio Description (AD) generation
MM-VID enables GPT-4V to understand hour-long videos and interactive streams by orchestrating specialized tools to transcribe visual and audio content into a coherent textual script.
Core Problem
Large Multimodal Models like GPT-4V have limited context windows, preventing them from directly processing long-form videos (hours) or maintaining narrative coherence across multiple episodes.
Why it matters:
- Current video models are typically trained on short clips (e.g., 10 seconds), failing to grasp long-term temporal dependencies in movies or sports
- Real-world applications like live-streaming or gaming require continuous reasoning over dynamic environments, which static clip-based models cannot handle
- Accessibility tools (Audio Descriptions) for long videos are expensive and slow to produce manually
Concrete Example:
In a 50-minute documentary, a standard model might identify a person in a single frame but fails to answer 'How did the protagonist's journey change over the last hour?' due to lack of long-term memory.
Key Novelty
Video-to-Script Generation Pipeline
- Treats video understanding as a text generation problem by converting the entire video into a detailed screenplay (script) first
- Uses GPT-4V to generate descriptions for short clips, then uses GPT-4 to stitch these snippets into a coherent long-form narrative including dialogue and action
- Integrates specialized expert tools (ASR, Scene Detection) to handle specific modalities before synthesis
Architecture
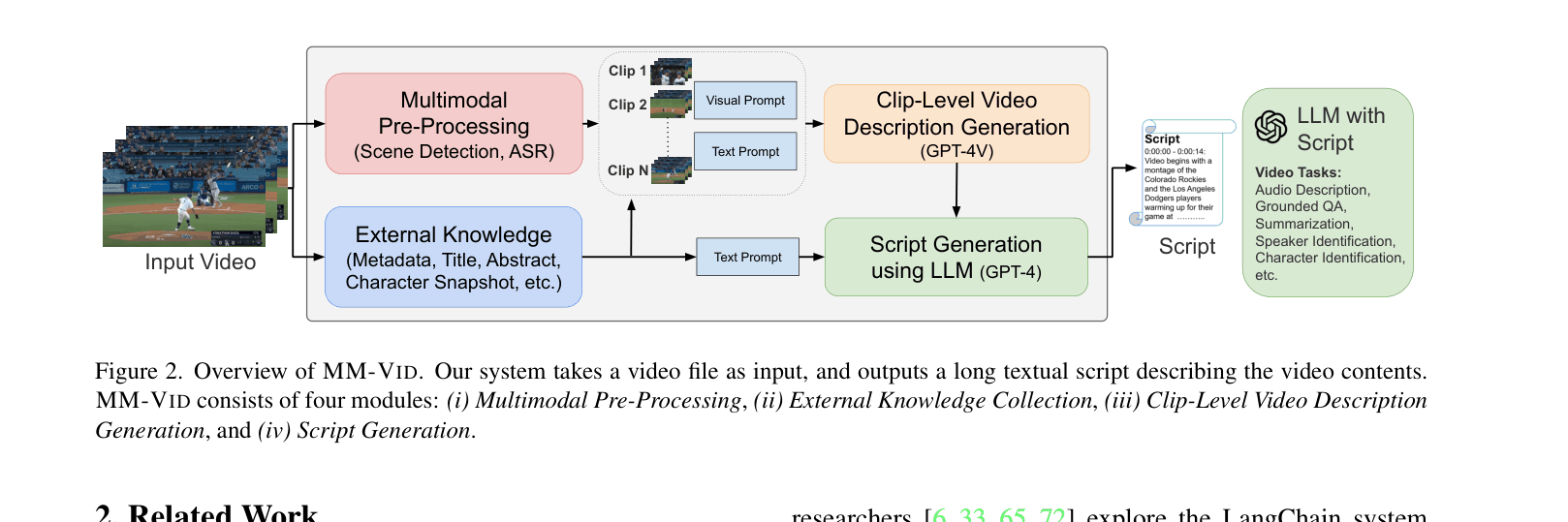
Overview of the MM-VID pipeline transforming video input into a textual script for downstream tasks
Evaluation Highlights
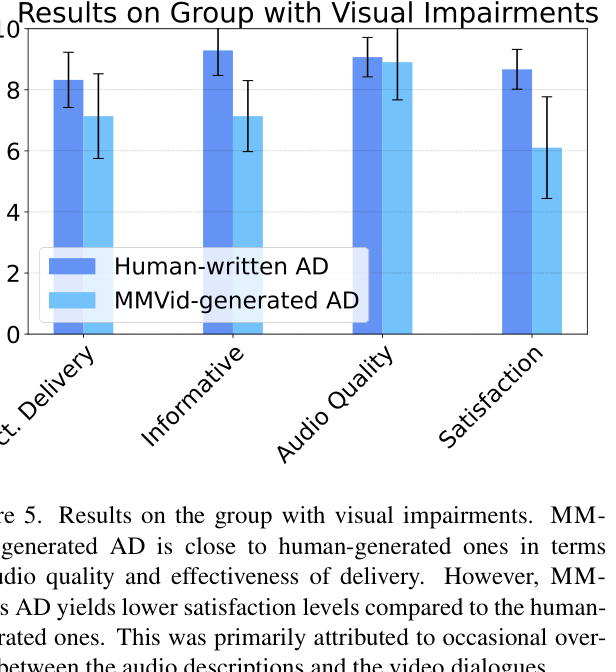
- Achieved 8.91/10 audio quality rating from visually impaired users for generated Audio Descriptions, comparable to human-crafted descriptions (9.07/10)
- Sighted users rated the timing/synchronization of MM-VID descriptions at 8.53/10, nearly matching human performance (8.59/10)
- Demonstrated zero-shot capability in playing Super Mario Bros and navigating iPhone GUIs by processing streaming frames
Breakthrough Assessment
7/10
Strong engineering system applying GPT-4V to long contexts via tool use. While architecturally it combines existing API calls, the 'script generation' paradigm effectively solves the context window bottleneck for video.