📝 Paper Summary
Personalized Image Generation
Unified Multimodal Large Language Models (MLLMs)
Reinforcement Learning for MLLMs
MM-R1 enables unified multimodal LLMs to perform zero-shot personalized image generation by integrating a cross-modal Chain-of-Thought reasoning strategy and optimizing it via Group Relative Policy Optimization.
Core Problem
Existing personalized image generation methods for MLLMs rely on subject-specific fine-tuning or external tokens, which limits scalability and fails to leverage the model's intrinsic reasoning capabilities.
Why it matters:
- Current methods like DreamBooth require costly per-subject optimization, making them inefficient for large-scale applications
- Approaches relying on external token mechanisms introduce complexity and limit the model's ability to generalize to new subjects without retraining
- The potential of unified MLLMs to perform personalization through inherent reasoning—aligning understanding and generation—remains underexplored
Concrete Example:
When a standard unified MLLM is asked to generate a personalized image, it often fails to maintain subject fidelity or text alignment because it attempts to generate directly without first grounding the subject's visual attributes or planning the layout, leading to generic or inconsistent outputs.
Key Novelty
Reasoning-Enhanced Personalization (MM-R1)
- Decomposes personalization into a 'reasoning' phase (understanding the reference image, extracting a subject image) and a 'generation' phase (creating the final image based on the reasoning plan)
- Uses a 'Cold-Start' strategy with a synthetic Chain-of-Thought dataset to teach the model this two-step reasoning pattern before applying reinforcement learning
- Applies Group Relative Policy Optimization (GRPO) with multi-aspect rewards (format, text alignment, subject similarity) to refine the model's reasoning and generation without needing a value network
Architecture
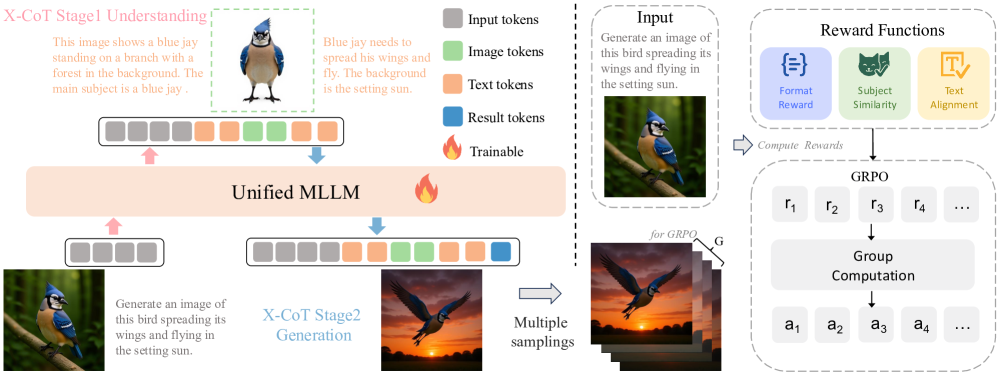
The MM-R1 framework pipeline, illustrating the X-CoT reasoning process and the GRPO training loop
Evaluation Highlights
- Achieves strong zero-shot personalization capabilities without subject-specific fine-tuning
- Demonstrates superior subject fidelity and text alignment compared to existing methods (qualitative claim, specific numbers not provided in excerpt)
- Successfully trains a unified backbone (Lumina-mGPT) to output structured reasoning (text + intermediate focus images) before final generation
Breakthrough Assessment
7/10
Novel application of GRPO and Chain-of-Thought to unified MLLM personalization, moving away from adapter/tuning-based methods. However, the paper snippet lacks concrete quantitative comparison tables against SOTA.