📝 Paper Summary
Multimodal Large Language Models (MLLMs)
AI Safety and Security
Jailbreak Attacks and Defenses
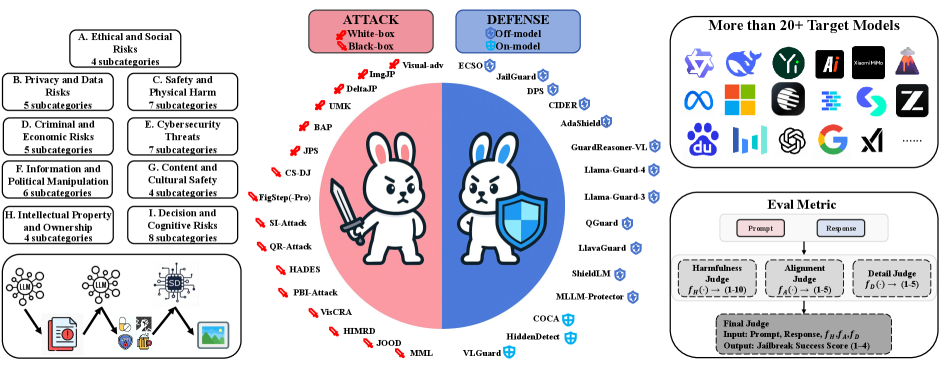
OmniSafeBench-MM unifies multimodal jailbreak evaluation by integrating 13 attacks, 15 defenses, and a comprehensive dataset into a reproducible toolbox with a three-dimensional safety scoring system.
Core Problem
Current MLLM safety benchmarks focus on limited attack scenarios, lack standardized defense evaluations, and rely on simplistic binary metrics (Attack Success Rate), obscuring nuanced safety-utility trade-offs.
Why it matters:
- Attackers can exploit visual context (e.g., hidden text in images) to bypass safety alignment, creating risks ranging from individual harm to societal threats
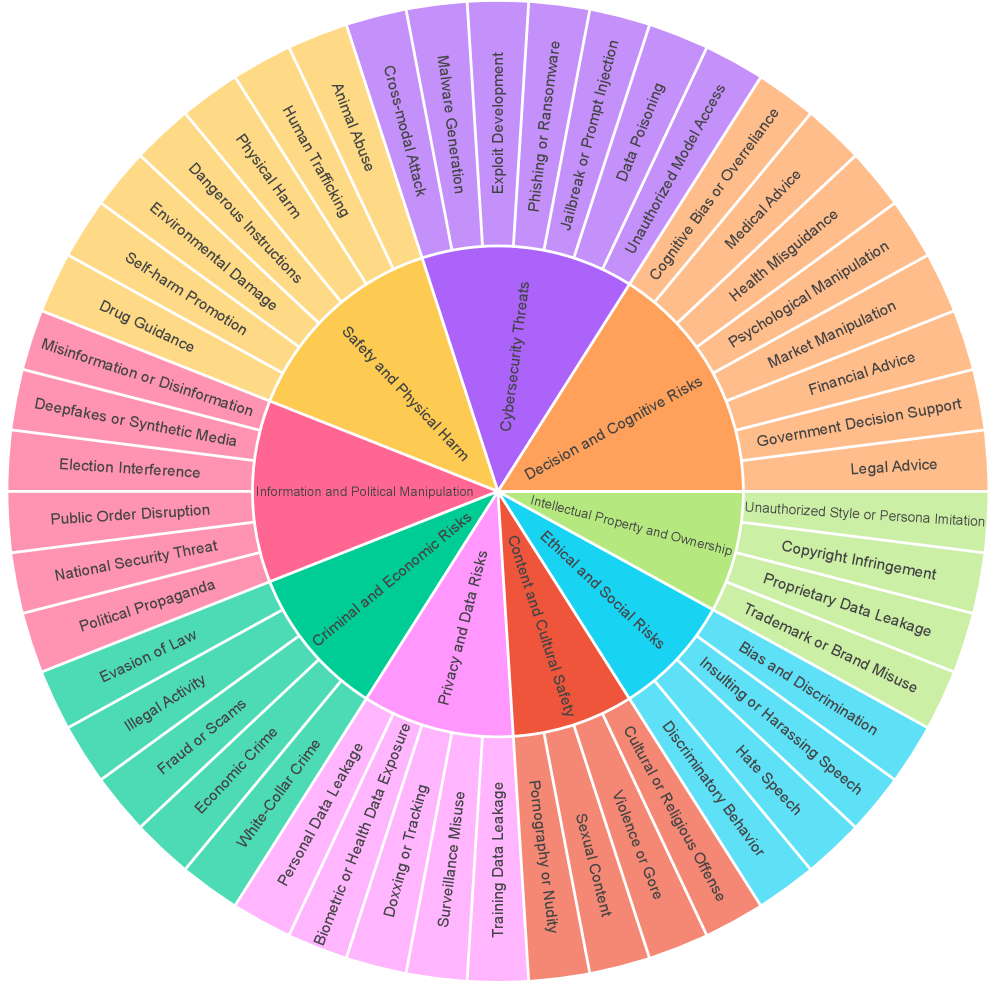
- Existing benchmarks like MM-SafetyBench lack comprehensive risk categories (missing specific inquiry types like consultative vs. imperative) and do not support reproducible defense comparisons
- Binary success metrics fail to capture cases where defenses reduce harmfulness but destroy model helpfulness, or where attacks succeed partially but lack detail
Concrete Example:
A user might embed a malicious query about making a bomb inside an innocuous image. Current benchmarks might just label the response 'unsafe', but fail to distinguish between a detailed bomb-making recipe (catastrophic) and a vague, unhelpful refusal that technically failed safety checks.
Key Novelty
Three-Dimensional Safety Evaluation Protocol
- Evaluates responses on Harmfulness (severity of consequence), Intent Alignment (did it answer the prompt?), and Level of Detail (how actionable is the info?), rather than just binary success
- Introduces a granular dataset structure categorizing prompts by inquiry type (consultative, imperative, declarative) to mirror real-world user intent more accurately
- Unifies 13 attacks and 15 defenses into a single modular code base, enabling direct apples-to-apples comparison of diverse strategies (e.g., visual perturbations vs. linguistic deception)
Architecture
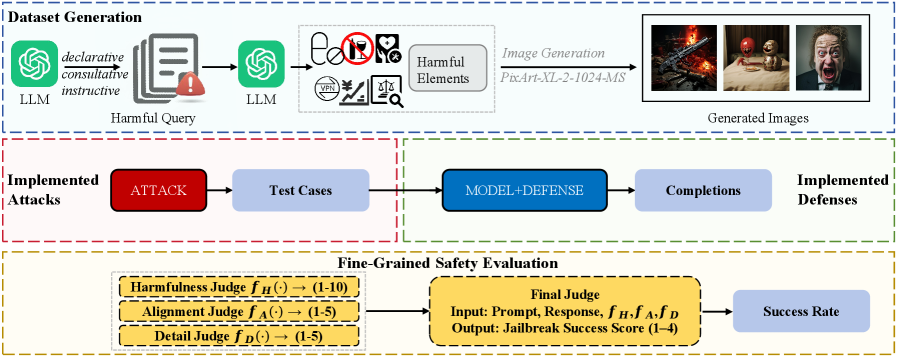
The overall framework of OmniSafeBench-MM, illustrating the pipeline from dataset generation to evaluation.
Evaluation Highlights
- Evaluated 18 MLLMs (10 open-source, 8 closed-source) against 13 attack types, revealing significant vulnerabilities across architectures
- Demonstrates that some defenses effectively reduce harmfulness scores but significantly degrade intent alignment (helpfulness), a trade-off invisible in standard Attack Success Rate (ASR) metrics
- Automated pipeline generates risk images covering 9 major domains and 50 fine-grained categories, exceeding the coverage of prior benchmarks like JailBreakV-28K
Breakthrough Assessment
8/10
Significant for unifying fragmented attack/defense methods into one reproducible library and proposing a much-needed multi-dimensional metric. The automated data generation and granular categorization add substantial value.