📝 Paper Summary
Medical Vision-Language Pretraining
Fundus Imaging Dataset Construction
Multi-modal Knowledge Transfer
MM-Retinal V2 introduces a multi-modal fundus dataset and the KeepFIT V2 method, which transfers expert knowledge from sparse image-text pairs into public categorical datasets via hybrid contrastive and generative injection.
Core Problem
Developing fundus foundation models currently relies on large-scale private image-text data because public data is scarce, typically unimodal (images only), or lacks rich textual descriptions.
Why it matters:
- Current state-of-the-art models (e.g., RET-CLIP, VisionUnite) are trained on private clinical data that is not released, hindering open research
- Existing public datasets mostly provide only categorical labels (e.g., 'glaucoma') rather than detailed diagnostic captions needed for vision-language alignment
- Clinical diagnosis requires multi-modal imaging (CFP, FFA, OCT), but most existing works utilize only Color Fundus Photography (CFP)
Concrete Example:
A standard classification model trained on public data might label an image simply as 'Diabetic Retinopathy', whereas an ophthalmologist's report would describe 'scattered microaneurysms and hard exudates in the macula'. Current public models fail to learn these fine-grained visual-linguistic associations.
Key Novelty
KeepFIT V2 (Knowledge-Enhanced Pretraining with Elite Knowledge Spark)
- Utilizes a small, high-quality 'elite' dataset (MM-Retinal V2) as a 'knowledge spark' to guide pretraining on larger public datasets that possess only categorical labels
- employs a 'Hybrid Image-Text Knowledge Injection' that combines contrastive learning (for global semantic concepts) and generative learning (for local appearance details) to align features
Architecture
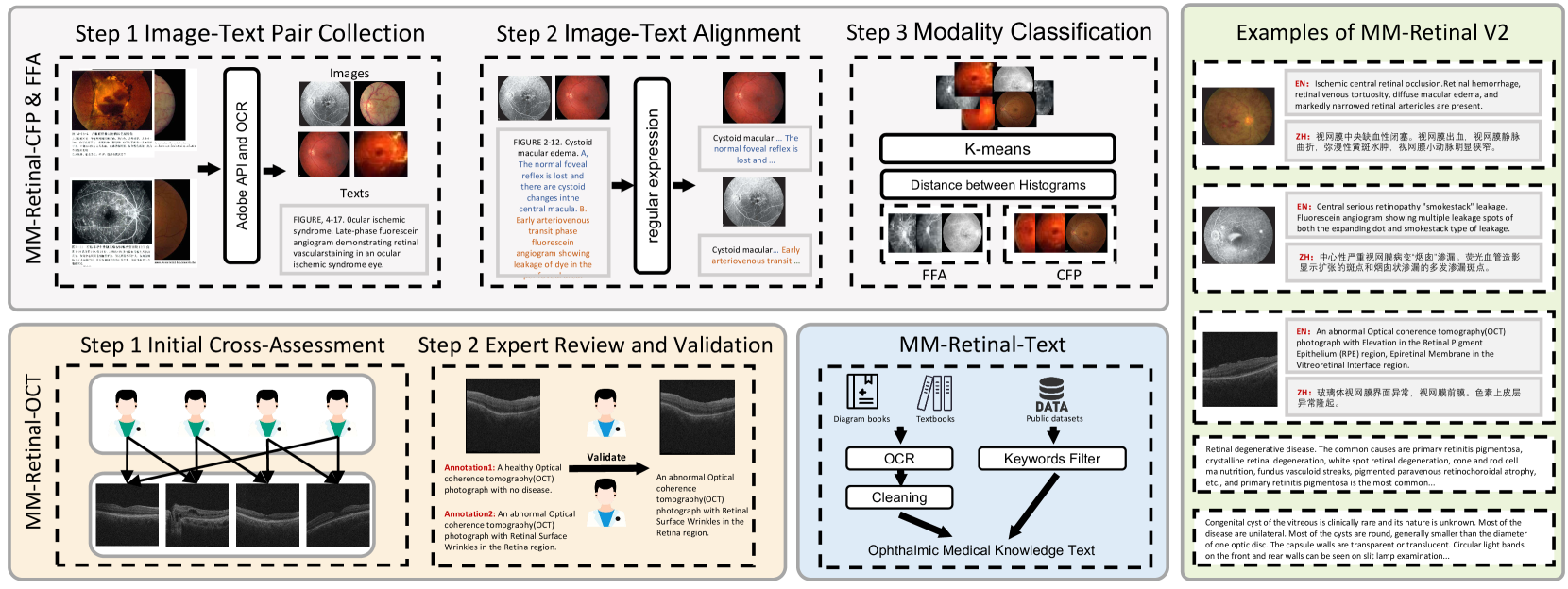
The dataset construction pipeline for MM-Retinal V2.
Evaluation Highlights
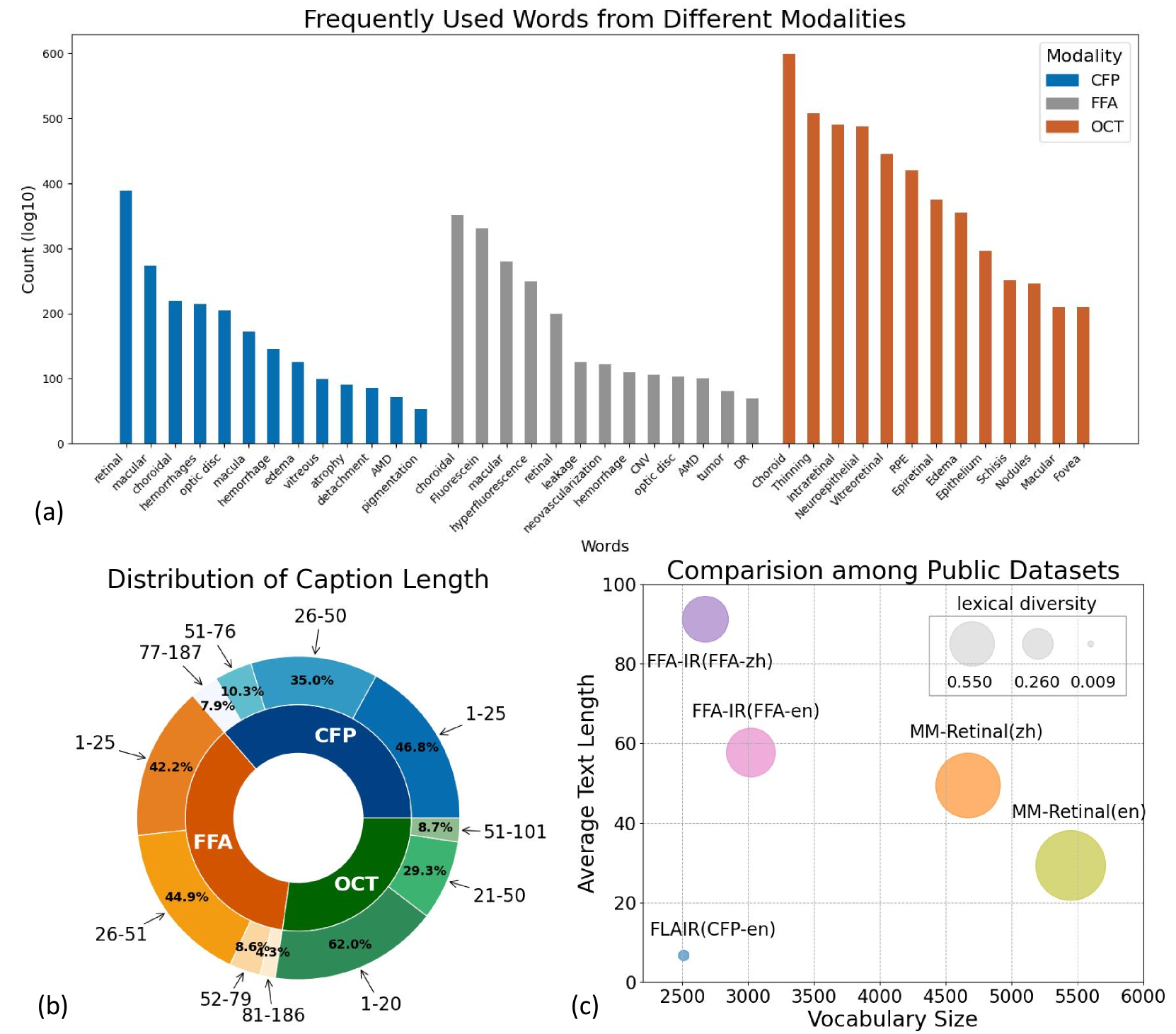
- Constructed MM-Retinal V2 with 17,341 total image-text pairs across CFP, FFA, and OCT modalities
- Compiled MM-Retinal-Text, a text-only corpus of 452,000 ophthalmic utterances for domain-specific text encoder pretraining
- Achieves competitive performance to models trained on massive private datasets (e.g., 190K+ pairs) by using only ~5K elite pairs per modality
Breakthrough Assessment
8/10
Significant contribution via the release of the first high-quality public multi-modal (CFP, FFA, OCT) image-text dataset, addressing a major scarcity bottleneck in medical VLP.