📝 Paper Summary
Text-to-Image Generation
Multi-modal Language Modeling
Instruction Tuning
CM3Leon applies text-only language modeling recipes—retrieval-augmented pretraining and instruction tuning—to a decoder-only multi-modal architecture, achieving state-of-the-art image generation efficiency and performance.
Core Problem
Diffusion models dominate image generation but lack text-reasoning capabilities, while traditional autoregressive image models are computationally expensive to train and hard to control via complex instructions.
Why it matters:
- Autoregressive models offer better global image coherence and can handle both text and image generation tasks within a single model, unlike diffusion
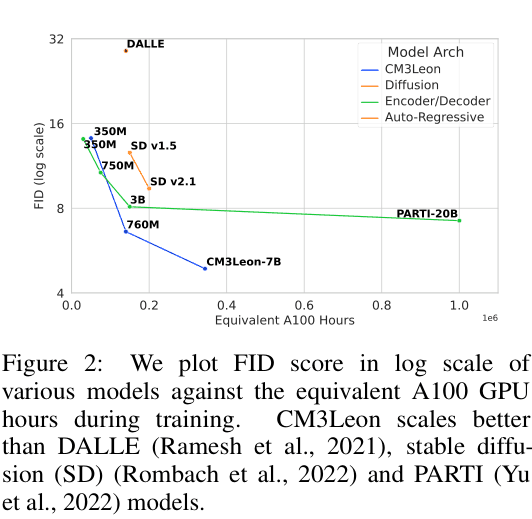
- Current token-based models require massive compute (e.g., PARTI-20B) to match diffusion quality
- Ethical concerns regarding image data sourcing are prevalent; this work proves SOTA results are possible using only licensed (Shutterstock) data
Concrete Example:
A user wants to 'Edit the image following the text instruction' by providing a photo of a woman and the text 'Make her an alien'. Standard autoregressive models struggle to preserve the original structure while following the edit. CM3Leon, via instruction tuning, successfully generates the edit while maintaining the original pose.
Key Novelty
CM3Leon (Chameleon)
- First multi-modal model to successfully adapt the 'text-only' recipe of large-scale retrieval-augmented pretraining followed by multi-task supervised fine-tuning (SFT)
- Introduces a self-contained Contrastive Decoding (CD-K) method for image generation that subtracts unconditional logits from conditional ones to improve quality without external classifiers
- Proves that retrieval augmentation allows autoregressive models to be extremely training-efficient (5x less compute than comparable models)
Architecture

Conceptual flow of CM3Leon's capabilities including text-to-image and structure-guided editing.
Evaluation Highlights
- Achieves zero-shot MS-COCO FID of 4.88 (CM3Leon-7B), setting a new state-of-the-art among autoregressive models
- Outperforms Google's PARTI-20B (FID 7.23) while using 5x less training compute
- Instruction-tuned model (SFT-CM3Leon-7B) achieves 61.6 CIDEr on MS-COCO Captioning (zero-shot), comparable to larger vision-language models
Breakthrough Assessment
9/10
Significantly shifts the paradigm by showing autoregressive models can beat diffusion in efficiency if trained like LLMs (retrieval + SFT), achieving SOTA with far less compute.